
Обработка на английском: Error 404 (Not Found)!!1
| Цифровая обработка фотографий для меня не правдива. | A digitally manipulated photograph is not true for me. |
| Я также знаю, что когда бужу его на несколько часов раньше, чем требуют его биологические часы, то я буквально лишаю его грёз, прерывая период сна, когда происходит обучение, формирование воспоминаний и обработка эмоций. | I also know that by waking him up hours before his natural biological clock tells him he’s ready, I’m literally robbing him of his dreams — the type of sleep most associated with learning, memory consolidation and emotional processing. |
| Идея состоит в том, чтобы процесс разделения для скрининга был столь же прост, как обработка образца мочи, крови или слюны, и этого реально достичь в течение следующих нескольких лет. | The idea here is that the separation process for screening could be as simple as processing a sample of urine, blood or saliva, which is a near-term possibility within the next few years. |
| Обработка отнимает вкус, который нужно восстановить с помощью добавок. | Processing removes flavor which has to be replaced through additives. |
| Обработка того охрененного количества алкоголя, что я посылал ей ежедневно. | Processing the copious amounts of alcohol I send its way daily. |
| Даже при помощи нашей программы распознавания лиц обработка такого количества информации займет много времени. | Even with our facial recognition programs, going through that much data is going to take a long time. |
| Обработка трупа с нитриловой резиной не оставляет следов улик, верно? | Handling a corpse with nitrile rubber does not leave trace evidence, all right? |
| Необходимо учитывать, что обработка многостраничных вопросников сопряжено с высокой вероятностью ошибок. | One should take into consideration the fact that many pages mean a higher potential to err. |
2. 1.2.3.1 Обработка данных в начале перевозки МДП. 1.2.3.1 Обработка данных в начале перевозки МДП. | Exchange of TIR transport information Data handling at the beginning of the TIR transport. |
| 2.3.2 Обработка данных, связанных с операциями МДП. | Data handling related to TIR operations Elements composing the TIR operation registration TIR operation start information. |
| 2.1.2.3.2 Обработка данных, связанных с операциями МДП. | Data handling related to TIR operations. |
| Также ведется сбор и обработка информации о состоянии окружающей среды, что имеет важное значение для обеспечения здоровья граждан. | As an important segment affecting the health condition of citizens, data on environment are collected and processed. |
| В порту Ловииса производится обработка как контейнерных, так и генеральных грузов. | General cargo handling is not a problem at all for Loviisa’s port. |
Обработка как общих грузов, так и контейнеров производится судами с использованием собственного оборудования. | Cargo handling, both for general cargo and containers, is limited, and ships have to use their own rigging. |
| Может быть элементарнейшая обработка металла — это слишком для твоего хора, занявшего двенадцатое место. | Maybe basic sheet metal work is just too much for your 12th place choir. |
| Обработка проводится женщинами, занимающимися кустарным промыслом, которые производят такие товары, как бутылки, которые становятся лампами путем нанесения краски и добавления электропроводки. | The refinishing is done by women artisans who produce such items as a bottle that they convert into a lamp by painting it and adding electric fittings. |
| Основное предназначение «КА5.Россыпь» — хранение и обработка фактических данных разведки и разработки россыпных месторождений. | PolyBoolean includes Boolean operations, basic polygon construction routines and polygon triangulation routines. |
Эти вопросы были выбраны для подробного рассмотрения, поскольку сбор и обработка относящихся к ним данных связаны с наибольшими расходами. | These topics were chosen for detailed consideration, as they were the most expensive topics to collect and process. |
| Проводятся исследования в области стратегии утилизации упаковочных отходов и обработка сточных вод. | Studies have been done on packaging waste and waste-water policies. |
| Пункт 7.5.7.1: Обработка и укладка грузов. | Paragraph 7.5.7.1: Handling and stowage of cargo. |
| З. Обработка и укладка контейнеров и контейнеров-цистерн. | Handling and stowage of containers and tank-containers. |
| Компания добывает лекарственные растения и лечебные травы силами местного населения, обработка сырья производится по определённым стандартам. Для сохранения более глубокого и свежего вкуса, чай поступает в продажу в специальных чайных пакетиках из фольги, уложенных в красочные коробки. | For the purpose of keeping taste and aroma, the production is offered to the market by means of foil and special packs. |
| Уход за растениями — обработка семян перед хранением и посадкой. | Plant care — treatment of seeds before storage and sowing. |
| Такая обработка обеспечивает более четкое представление по сокращению отраженного света от внешних и внутренних поверхностей объектива. | This treatment provides a better view by reducing the light reflected on the external surfaces and internal lens. |
| Разные коммерческие перевозки, не предусмотренные в других разделах, транспортно-экспедиторская обработка грузов и таможенная очистка. | Miscellaneous freight and cartage not provided elsewhere, freight forwarding and customs clearance charges. |
| Основной специализацией компании является обработка алмазов, а также оптовая и розничная продажа алмазов, ювелирных украшений и часов. | The company still focuses primarily on the cutting of diamonds and the wholesale and retail of set diamonds, loose polished diamonds, gold jewellery and watches. |
| Эти обозначения показывают, является ли обработка носителя частью соответствующей задачи, и должен ли носитель быть полностью без ошибок или уже может быть поврежден. | These symbols indicate whether processing a medium is part of the respective task, and if the medium needs be completely error free or may already be damaged. |
| Обработка поверхности производится порошковой технологией в цветах, выбранных заказчиком. Стандартно используется RAL 7032. | The surface is powder coated in the shade RAL 7032 by default, but the desired shade may be specified by the customer. |
| Обработка данных переписи первоначально осуществлялась путем механического подсчета, затем стали использоваться устройства автоматического подсчета, а в настоящее время — методы компьютерной обработки информации со скоростью, которую ранее невозможно было себе и представить. | Census data processing began with hand tallies and progressed to the early key punch methods, to computers processing data at previously unimagined speed. |
| Струйная обработка сухим льдом Cold Jet — это лучшее средство для обеспечения гладкой поверхности. | Cold Jet dry ice blasting is the logical choice when no surface roughness is desired. |
| До последнего времени эти усилия носили в основном структурный характер: проводились террасирование, контурная обработка, удаление ила, водоотвод и т.д. | Until recently, such efforts mainly emphasized structural works such as terracing, contours, silt traps, diversions, etc. |
| Сбор и обработка на борту судна, сдача в приемные. | On-board collection and processing of waste; deposit at reception facilities. |
| Таким образом, обработка шлака не оказывает влияния на качество стали. | Thus the steel quality is not influenced by this slag treatment. |
| Обработка шлаков производится по нескольким технологиям. | The slag is treated in several ways. |
Эти изменения стали возможны благодаря секторам, в которых заработная плата намного выше среднего уровня, таким, как портовое хозяйство, строительство и обработка телефонных звонков. | Sectors paying wages that are far above average pay levels, such as ports, the construction industry and call centres, have contributed to these changes. |
| Предварительная обработка должна включать обезвоживание для предотвращения взрывных реакций при соприкосновении с металлическим натрием. | Pre-treatment should include dewatering to avoid explosive reactions with metallic sodium. |
| В основе этого алгоритма лежат антропометрическая, графическая и векторная обработка цифровой информации. | This algorithm is based on anthropometric, graphic, and vector processing of digital information. |
| Важно отметить, что их обработка потребует дополнительных проверок на дублирующие записи и определения того, какая из дублирующих записей должна быть признана действительной. | Importantly, processing will be required to undertake additional checks for duplicated records and determine which of the records is to be retained. |
| Самыми эффективными из них являются фумиганты, применяемые либо в качестве смесей, либо в процессе последовательного применения, или нехимические методы, такие, как прививка и обработка паром. | The most effective of these were fumigants, either as mixtures or sequential applications, or non-chemical techniques, such as grafting and steaming. |
| Обработка и рассылка свидетельств о праве на получение пособия. | Processing and mailing of certificates of entitlement. |
| Вопрос. Струйная обработка сухим льдом повреждает основание? | Q: Will dry ice blasting damage the substrate? |
| Одним из методов снижения выбросов, который в ограниченном масштабе применяется в некоторых регионах, является обработка отводимого воздуха с помощью скрубберов или капельных биофильтров. | Treatment of exhaust air by acid scrubber or biotrickling filters is an option that has been applied on a very restricted scale in a few regions. |
| Некоторые потоки отходов имеют весьма высокое содержание ртути, поэтому требуется дополнительная предварительная обработка отходов. | Some waste streams have very highly variable mercury content so additional waste pre-treatment is required. |
| Ц: Обработка Датчик движения должен обеспечивать точность обработки поступающей информации, на основании которой рассчитываются данные о движении. | O.Processing The motion sensor must ensure that processing of input to derive motion data is accurate. |
| Тепловая обработка тонких деталей — глубинная печь, масло, вода. | Thermal treatment of slender parts — pit furnace, oil, water. |
| Проводились обработка и комплексный анализ спутниковых и наземных данных для компьютерного моделирования крупномасштабных волновых процессов в ионосфере и атмосфере. | Satellite and ground-based data were processed and analysed carefully for the computer modelling of large-scale wave processes in the ionosphere and atmosphere. |
| В вашем коде должна быть предусмотрена обработка таких свойств. | Make sure your code is robust enough to handle these cases. |
| Возможно, вам будет полезна статья Outlook не отвечает, зависает на этапе Обработка или перестает работать. | You may also want to see Outlook not responding, stuck at Processing, stopped working, freezes, or hangs. |
| Обработка волны — создание, реализация и запуск в производство с помощью запланированной пакетной или ручной обработки волн. | Wave processing — Create, implement, and release work using batch-scheduled or manual processing of waves. |
| О том, что делать, если ваш платеж отклонен, отменен или его обработка приостановлена, читайте здесь. | Learn more about what to do if your payment is declined, cancelled, or on hold. |
| Обработка входа зависит от того, использует ваше приложение маркер доступа или код авторизации. | How you handle a login depends on whether your app uses an access token or an authorization code. |
| Как правило, обработка платежа кредитной картой или банковским переводом в реальном времени занимает один рабочий день. Показ объявлений будет возобновлен в течение суток после этой процедуры. | Payments by credit card or real-time bank transfer normally process within 1 business day, and your ads will be able to run within 24 hours after that. |
| Получение заказов на покупку или поступлений продуктов в форме Обработка счета-фактуры. | Retrieve purchase orders or product receipts in the Update facture form. |
| Извлечение данных заказа на покупку или поступления продуктов из формы Обработка счета-фактуры. | Retrieve purchase order or product receipt information from the Update facture form. |
| В этом разделе описывается настройка параметров задач, таких как планирование встречи, выставление накладных поставщиков, планирование транзита, обработка входящих или исходящих загрузок и отгрузка. | This topic describes the parameter setup for tasks such as appointment scheduling, vendor invoicing, transit planning, inbound or outbound load processing, and shipping. |
| Обработка может проводиться как внутри корпуса предмета очистки (напр., трансформатор, загрязнённый ПХД), так и в специальном реакционном сосуде. | Treatment can take place either in situ (e.g., PCB-contaminated transformers) or ex situ in a reaction vessel. |
| 2. Утверждение и обработка возврата денежных средств по чеку | 2. Approve and process a check refund |
| Обработка заработной платы пересмотрена в Microsoft Dynamics AX 2012 R2 и теперь обеспечивает более последовательный пользовательский интерфейс. | Payroll processing was redesigned in Microsoft Dynamics AX 2012 R2 and now provides a more consistent user interface. |
| Обработка регистраций времени и посещаемости [AX 2012] | Process time and attendance registrations [AX 2012] |
| Обработка целых конденсаторов и трансформаторов возможна после уменьшения их габаритов путём измельчения. | Treatment of whole capacitors and transformers could be carried out following size reduction through shredding. |
| Другие результаты | |
Карта сайта
Карта сайтаИнституты и высшие школы
К сожалению, запрашиваемая страница не найдена.
Воспользуйтесь поиском или картой сайта:
<img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php. gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/>
<img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/> <img src=»/bitrix/images/fileman/htmledit2/php.
gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/>
<img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/> <img src=»/bitrix/images/fileman/htmledit2/php. gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/>Карта сайта
gif» border=»0″/><img src=»/bitrix/images/fileman/htmledit2/php.gif» border=»0″/>Карта сайтаКак научиться пересказывать текст на английском языке
Пересказ интересного текста
Лучше сделать пересказ интересного текста. Выбирайте простые, развернутые, известные темы. Запомнить информацию легче, если разбираешься. Вам не разрешают самостоятельно выбрать текст, а окончательная тема не интересна? Играйте на публику. Эмоциональный рассказ, жестикуляция, возбужденный голос вселяет доверие, представляет объект интересным.
Рассказывая текст уверенно и без заминок, вы завоюете любовь аудитории. Неточности в сюжете могут не заметить. Так вы передадите эмоции собеседнику.
Выборочный пересказ текста
Выборочный пересказ на английском языке легче написать. Не обязательно знать детали текста. Нет необходимости использовать новую лексику. Процесс легче предыдущего. Вид выборочного пересказа английского текста учит обрабатывать информацию, выкидывать ненужные фрагменты, глобально понимать написанное. Главные показатели — краткость, умение очертить ситуацию происходящего в 7-10 предложениях. Написание подробного и выборочного пересказа отличаются.
Главные показатели — краткость, умение очертить ситуацию происходящего в 7-10 предложениях. Написание подробного и выборочного пересказа отличаются.
Как делать выборочный пересказ текста:
- Прочитайте текст 3-4 раза. Не обязательно переводить все неизвестные слова. Детализованный перевод уместен при подробном пересказе. Цель стоит в глобальном понимании написанного.
- Определите главную мысль, тему текста. Выпишите тезисы в тетрадь.
- Выделите маркером 3-5 предложений, которые помогут вам сделать пересказ.
- Перескажите текст на английском языке, не разбивая на абзацы. Если по-английски с первого раза не получается, перескажите сначала по-русски.
- После формулировки по-английски, повторите готовый пересказ еще 1-2 раза. Сделайте часовой перерыв, отдохните. Информация лучше усвоится. Займитесь своими делами. Спустя час повторите еще раз английский пересказ.
Сделать оригинальный пересказ не трудно. Правильно поставленная задача и творческий подход обязательно принесут свои плоды: научат обрабатывать информацию, подарят удовольствие и удовлетворение.
Правильно поставленная задача и творческий подход обязательно принесут свои плоды: научат обрабатывать информацию, подарят удовольствие и удовлетворение.
Теперь вы знаете, как научиться пересказывать на английском. Воспользуйтесь нашими советами, и у вас всё получится!
Испано-английский перевод теперь доступен для всех лифтов центров обработки данных
Корпорация ServerLIFT объявляет о немедленной доступности двуязычной испано-английской документации, касающейся всех лифтов и аксессуаров для центров обработки данных.
Представленные для расширения доступа клиентов и в соответствии с европейскими правилами, новейшие дополнения к библиотеке двуязычных инструкций продукта, руководств оператора, спецификаций, брошюр и наклеек ServerLIFT имеют решающее значение для оказания помощи растущей глобальной аудитории. Испанский язык является официальным языком 20 стран и претендует на второе место по количеству носителей языка в мире.
«Это объявление отражает усилия по глобализации ServerLIFT. Двуязычная информация поможет поддерживать высокий стандарт безопасности с испаноязычной базой пользователей, которая не знакома с решением. Это сделает ServerLIFT более доступным для [нашего] региона и поддержит [наши] образовательные усилия », — говорит Арье Бройде из RLA Power в Коста-Рике.
Двуязычная информация поможет поддерживать высокий стандарт безопасности с испаноязычной базой пользователей, которая не знакома с решением. Это сделает ServerLIFT более доступным для [нашего] региона и поддержит [наши] образовательные усилия », — говорит Арье Бройде из RLA Power в Коста-Рике.
Продукты ServerLIFT упрощают работу центра обработки данных и обеспечивают безопасный выбор для транспортировки, размещения, установки и удаления серверного оборудования. ServerLIFT разработал перевод на испанский язык для таких продуктов, как:
Подъемные машины:
- ServerLIFT SL-500X: Лучшее универсальное решение с легким электрическим подъемом в одно касание.
- ServerLIFT SL-500FX: Идеальный выбор для помещений с широкими проходами.
- ServerLIFT SL-1000X: Лучший лифт ЦОД, сертифицированный по безопасности.
- ServerLIFT SL-350X: Премиальный вариант с электрическим подъёмником с ручной коленчатой рукояткой Отлично подходит для нечастых ходов.


Add-Ons:
- Удлинитель подъема LE-500X и LE-1000X: Удаляет оборудование из ящиков и с поддонов.
- RL-500 Riser: идеально подходит для установки на более высокие серверные стойки.
- Рельсовый подъемник RS-500X: Направляет оборудование внутрь и из направляющих.
Вся документация, описанная выше, доступна немедленно по запросу. Пользователи ServerLIFT могут получить документацию по испанскому языку по телефону (602) 254-1557 или по электронной почте [email protected].
Выпуск испано-английских двуязычных инструкций по продуктам, руководств для операторов и других материалов следует за хорошо известной новостью о доступности Французско-английский переводы для оборудования ServerLIFT.
(Оригинальный пресс-релиз можно найти на PRWeb.)
Курсы английского языка для детей в Санкт-Петербурге
,Занятия английским в удобном формате — онлайн или оффлайн в 20 языковых школах Helen Doron в СПБ.
 Английский с нуля до эффективной подготовки к тестам и свободного владения иностранным языком.
Английский с нуля до эффективной подготовки к тестам и свободного владения иностранным языком. Helen Doron — международная сеть школ английского языка для детей и подростков.
Свободно общаться на английском заграницей и с англоязычными друзьями, сдать экзамены в лучшие ВУЗы, смотреть фильмы и читать книги на английском, интуитивно понимать язык на уровне носителя — все это возможно для студентов наших курсов.
В 37 странах дети от 3 месяцев до 12 лет и подростки до 19 лет учат английский по методике Helen Doron — с удовольствием погружаясь в игры, творчество, создавая собственные и командные проекты, мюзиклы, театральные постановки, участвуя в квестах и научных экспериментах.
Мы учим английский как второй родной язык, поэтому занятия проходят полностью на английском языке для любого уровня. Полное погружение в язык приносит отличные результаты!
Мы формируем среду, в которой английский язык для детей перестает быть иностранным и становится языком выражения мыслей.
Для каждого возраста — свой уникальный курс английского
В компании Helen Doron разработано более 30 курсов английского для каждого возраста отдельно: для малышей, дошкольников, школьников и подростков. Задания и темы соответствуют возрасту и увлекают учеников. Занимаясь со сверстниками, дети и подростки учатся свободно общаться на английском и находят новых друзей.
Helen Doron English в цифрах
1985
год основания компании
1200
школ в мире
15
городов России
Helen Doron English Cанкт-Петербург, Адмиралтейский район917-73-41
[email protected]
Россия
196084
Cанкт-Петербург
улица Парфеновская, д. 9, корп. 1, стр. 1, 2 этаж
949-32-00
[email protected]
Россия
199397
Cанкт-Петербург
ул. Беринга, д. 1
941-95-22
viborgskiy.
 [email protected]
[email protected] Россия
194356
Cанкт-Петербург
пр-т Луначарского д.13, корп. 1
922-23-09
[email protected]
Россия
194358
Cанкт-Петербург
ул.Валерия Гаврилина, д. 11, корп.1
907-73-53
[email protected]
Россия
195267
Cанкт-Петербург
ул. Ушинского, д. 2, корп. 1
926-15-05
[email protected]
Россия
195220
Cанкт-Петербург
ул. Богословская, 4
905-93-59
[email protected]
Россия
198260
Cанкт-Петербург
улица Солдата Корзуна 4
923-87-50
[email protected]
Россия
195030
Cанкт-Петербург
ул. Лазо, д.5
Лазо, д.5
715-50-28
[email protected]
Россия
198096
Cанкт-Петербург
ул. Маршала Казакова, д. 26
916-86-38
[email protected]
Россия
198206
Cанкт-Петербург
ул. Адмирала Трибуца, 8
914-48-13
[email protected]
Россия
196211
Cанкт-Петербург
ул. Типанова, д.27/39
974-00-02
[email protected]
Россия
193079
Cанкт-Петербург
Дальневосточный пр-кт, д. 14, к. 1
929-02-46
[email protected]
Россия
197110
Cанкт-Петербург
ул. Глухая Зеленина, д. 6
995-05-06
primorsky.
 [email protected]
[email protected] Россия
197082
Cанкт-Петербург
Богатырский проспект, 60, корп. 1
929-02-56
[email protected]
Россия
197374
Cанкт-Петербург
Приморский пр., д. 137 корп. 1
951-90-90
[email protected]
Россия
197350
Cанкт-Петербург
пр. Королева, д. 59 корп. 2
904-69-23
[email protected]
Россия
197375
Cанкт-Петербург
ул. Главная, д. 25
988-39-93
[email protected]
Россия
192284
Cанкт-Петербург
Загребский б-р, д.9
970-19-90
[email protected]
Россия
187032
Cанкт-Петербург
Ладожский бульвар д. 1, к1
1, к1
920-20-36
[email protected]
Россия
188691
Cанкт-Петербург
ул.Венская, д.4, корп.1
+7(911)223-92-41
[email protected]
Россия
196603
Cанкт-Петербург
Колокольный пер., д. 5
Согласие на обработку данных — English Language Academy Oxbridge
Пользователь, оформляя заявку на сайте http://oxbridge1991.ru (далее – Сайт), соглашается с условиями настоящего Согласия на обработку персональных данных (далее — Согласие) в соответствии со ст. 9 Федерального закона от 27.07.2006 № 152-ФЗ «О персональных данных». Принятием (акцептом) оферты Согласия является отправка заявки с Сайта.
Пользователь дает свое согласие Учебный центр английского языка Oxbridge — English Language Academy (ELA) (далее — Оператор) на обработку своих персональных данных со следующими условиями:
1. Данное Согласие дается на обработку персональных данных как без, так и с использованием средств автоматизации.
Данное Согласие дается на обработку персональных данных как без, так и с использованием средств автоматизации.
2. Согласие распространяется на следующую информацию: фамилия, имя, отчество, телефон, электронная почта.
3. Согласие на обработку персональных данных дается в целях предоставления Пользователю ответа на заявку, дальнейшего заключения и выполнения обязательств по договорам, осуществления клиентской поддержки, информирования об услугах, которые, по мнению Оператора, могут представлять интерес для Пользователя, проведения опросов и маркетинговых исследований.
4. Пользователь, предоставляет Оператору право осуществлять следующие действия (операции) с персональными данными: сбор, запись, систематизация, накопление, хранение, уточнение (обновление, изменение), использование, обезличивание, блокирование, удаление и уничтожение, передача третьим лицам, с согласия субъекта персональных данных и соблюдением мер, обеспечивающих защиту персональных данных от несанкционированного доступа.
6. Персональные данные обрабатываются Оператором до завершения всех необходимых процедур. Также обработка может быть прекращена по запросу Пользователя на электронную почту: [email protected].
7. Пользователь подтверждает, что, давая Согласие, он действует свободно, своей волей и в своем интересе.
8. Настоящее Согласие действует бессрочно до момента прекращения обработки персональных данных по причинам, указанным в п.6 данного документа.
Оператор обработки данных (знание английского языка)
Oras: Chisinau
Studii: Superioare
Experienta de munca: Orice
Salariu: Negociabil
Grafic de munca: Full-time
№
588750, 04. 09.2012
09.2012
— Высшее образование
— Отличное знание английского языка (знание другого иностранного языка будет рассматриваться как преимущество)
— Компьютерная грамотность: MS Office, Excel
— Способность к быстрому обучению
— Коммуникативные навыки, способность работать в команде
Сменный график работы:
7.00 – 14.30
14.30 – 22.00
Частичная занятость по субботам.
Пожалуйста, отправляйте свое резюме на английском языке по адресу: [email protected] с указанием должности в теме пиьсма.
Только отобранные кандидаты будут приглашены на интервью. Inapoi Inainte
Ataseaza CV-ul Creaza CV
Ataseaza CV-ul
Alegeti jobulAlegeti jobul
Creaza cel mai bun CV din Moldova!
Completeaza CV-ul pe Rabota. md
md
si trimite-l in orice companie cu un singur click!
Ai deja un CV pe site-ul nostru?
Intra pe site
Creaza cel mai bun CV din Moldova!
Completeaza CV-ul pe Rabota.md
si trimite-l in orice companie cu un singur click!
Ai deja un CV pe site-ul nostru?
Creaza CV
Trimite CV-ul
Alegeti jobulAlegeti jobul
Inchide
CV-ul a fost expediat!
Inchideопределение обработки запроса | Английский словарь для учащихся
процесс
( процессов во множественном числе и от третьего лица ) ( обработка причастия настоящего ) ( обработано прошедшее время и причастие прошедшего времени )
1 n-count Процесс — это последовательность действий, которые выполняются для достижения определенного результата.
oft supp N, N of n
Было достигнуто полное согласие начать мирный процесс как можно скорее … Лучший способ продолжить — это процесс ликвидации.
2 n-count Процесс — это ряд событий, которые происходят естественным образом и приводят к биологическим или химическим изменениям.
Возникает у пожилых мужчин, по-видимому, как часть процесса старения …
3 глагол Когда сырье или пищевые продукты перерабатываются, их готовят на фабриках, прежде чем использовать или продать.
… рыба, обработанная замораживанием, консервированием или копчением … be V-ed
Материал будет переработан в пластиковые гранулы. будет преобразовано в n
… диеты с высоким содержанием рафинированных и обработанных пищевых продуктов. V-ed
Process — тоже существительное., N-count
… стоимость реинжиниринга производственного процесса.
♦ обработка n-uncount usu с supp
Америка отправила хлопок в Англию для переработки.
4 глагол Когда люди обрабатывают информацию, они пропускают ее через систему или в компьютер, чтобы обработать ее.
… средства для обработки данных и право на публикацию результатов … V n
♦ обработка n-uncount supp N
… обработка данных …
→
обработка текста
5 глагол Когда люди рассматриваются чиновниками, их дела рассматриваются поэтапно, и они переходят от одного этапа процесса к другому.
usu passive
Обработка пациентов в отделении занимала более двух часов. V-ed
6 Если вы что-то делаете, значит, вы начали это делать и все еще делаете.
♦ в процессе фраза V перегиб, usu v-link PHR
Администрация находится в процессе составления мирного плана …
7 Если вы делаете что-то, а в процессе вы делаете что-то еще, вы делаете вторую вещь как часть выполнения первой.
♦ в процессе фраза PHR с cl
Вы должны позволить нам бороться за себя, даже если мы должны умереть в процессе.
Условия обработки данных — английский
В связи с Услугами, предоставляемыми в соответствии с соглашением об обслуживании («Соглашение о предоставлении услуг , ») поставщиком услуг в качестве обработчика данных, являющимся Imprima или соответствующим Аффилированным лицом, которое является стороной Соглашения об обслуживании (соответствующая сторона, именуемая «Поставщик услуг , ») Клиенту в качестве контроллера данных (« Клиент »), стороны согласились, что эти условия обработки данных («Условия ») должны применяться для того, чтобы соблюдать обязательства, возложенные на Клиента в соответствии с Законом о защите данных.Эти Условия должны быть включены в Соглашение о предоставлении услуг посредством ссылки.
, ПРОДОЛЖАЯ ПРЕДОСТАВЛЯТЬ ИЛИ ПОЛУЧАТЬ УСЛУГИ, В зависимости от того, что применимо, СТОРОНЫ СОГЛАШАЕТСЯ С ДАННЫМИ УСЛОВИЯМИ.
ТЕПЕРЬ НАСТОЯЩИМ СОГЛАСОВАНО о следующем:
- ОПРЕДЕЛЕНИЯ
- В настоящих Условиях слова с заглавной буквы имеют значение, определенное в Соглашении о предоставлении услуг, если в настоящих Условиях прямо не указано иное ниже или в других местах настоящих Условий. :
- « Аффилированное лицо » означает любое лицо, которое прямо или косвенно контролирует, контролируется или находится под общим контролем с стороной время от времени в течение Срока действия;
- «Закон о защите данных » означает законы о конфиденциальности данных, применимые к обработке в связи с Услугами, включая, где это применимо, Регламент (ЕС) 2016/679 с поправками или заменой любым последующим Регламентом, Директивой или другим правовой документ Европейского Союза, в том числе Общий регламент по защите данных или аналогичный закон, или применимые законы о конфиденциальности данных любой другой соответствующей юрисдикции;
- « Конечный пользователь » имеет значение, определенное в Соглашении о предоставлении услуг;
- « Услуги » означает услуги, описанные в Соглашении о предоставлении услуг и в разделе ниже;
- « договорных положений » означает стандартные договорные положения Европейской комиссии о передаче персональных данных за границу, с поправками или заменой время от времени, или любой эквивалентный набор договорных положений, утвержденных для использования в соответствии с Законом о защите данных; и
- « Персональные данные клиента » означает персональные данные, обрабатываемые нами в связи с Услугами, как описано ниже. В соответствии с пунктом 2.2 сюда могут входить личные данные Партнерской программы Клиента.
- Слова « субъект данных », « личные данные », « обработка » и их варианты, « контроллер » и « процессор » имеют значение, присвоенное им в Законе о защите данных. .
- В настоящих Условиях слова с заглавной буквы имеют значение, определенное в Соглашении о предоставлении услуг, если в настоящих Условиях прямо не указано иное ниже или в других местах настоящих Условий. :
- НАЗНАЧЕНИЕ
- Клиент назначается его Аффилированными лицами и Конечными пользователями для предоставления и управления различными услугами, включая Услуги, от их имени.Соответственно, Персональные данные Клиента могут содержать персональные данные, в отношении которых Аффилированные лица Клиента и Конечные пользователи являются контролерами. Клиент подтверждает, что он уполномочен сообщать Поставщику услуг любые инструкции или другие требования от имени Аффилированных лиц Клиента и Конечных пользователей в отношении обработки Персональных данных Клиента Поставщиком услуг в связи с Услугами.
- Поставщик услуг назначается Клиентом для обработки Персональных данных Клиента от имени Клиента и / или Аффилированных лиц Клиента и / или Конечных пользователей, в зависимости от обстоятельств, когда это необходимо для предоставления Услуг или по иной договоренности сторон. на письме.
- Клиент назначается его Аффилированными лицами и Конечными пользователями для предоставления и управления различными услугами, включая Услуги, от их имени.Соответственно, Персональные данные Клиента могут содержать персональные данные, в отношении которых Аффилированные лица Клиента и Конечные пользователи являются контролерами. Клиент подтверждает, что он уполномочен сообщать Поставщику услуг любые инструкции или другие требования от имени Аффилированных лиц Клиента и Конечных пользователей в отношении обработки Персональных данных Клиента Поставщиком услуг в связи с Услугами.
- ПРОДОЛЖИТЕЛЬНОСТЬ
- Настоящие Условия вступают в силу на более раннюю из следующих дат: (i) дата их исполнения или (ii) дата вступления в силу Соглашения о предоставлении услуг (« Дата вступления в силу ») и будет оставаться в полной силе до прекращения или истечения срока действия Соглашения о предоставлении услуг («Срок действия , »).
- УСЛУГИ
- Поставщик услуг может выполнять обработку Персональных данных клиента, как описано ниже:
- Описание услуг: Облачные услуги VDR Data Room.
- Предмет обработки: Обработка, связанная с предоставлением Услуг.
- Продолжительность обработки: В течение срока действия Соглашения о предоставлении услуг.
- Характер и цель обработки: размещение личных данных в комнате данных и предоставление конечным пользователям доступа к личным данным клиентов и их обработки в рамках Услуг.
- Тип персональных данных: данные о занятости, данные акционеров, данные клиентов, бизнес-данные, данные о продажах, финансовые данные и т. Д.
- Категории субъектов данных: персонал, консультанты, акционеры, клиенты и другие лица.
- Поставщик услуг может выполнять обработку Персональных данных клиента, как описано ниже:
- СОБЛЮДЕНИЕ ЗАЩИТЫ ДАННЫХ
- В отношении обработки Персональных данных Клиента в течение Срока, если иное не предусмотрено законом, Поставщик услуг соглашается:
- соблюдать Закон о защите данных в отношении их обработки Персональных данных Клиента;
- обрабатывать Персональные данные Клиента только в соответствии с требованиями, предъявляемыми к Услугам, в соответствии с документально оформленными законными инструкциями, которые Клиент разумно предоставляет время от времени в контексте Услуг, а также для внутренней бизнес-аналитики. Клиент гарантирует и постоянно заявляет, что его инструкции не приведут к нарушению Закона Поставщиком услуг;
- сообщить Клиенту, если, по его мнению, инструкция нарушает Закон о защите данных;
- гарантировать, что весь персонал, уполномоченный Поставщиком услуг для обработки Персональных данных Клиента, взял на себя обязательство соблюдать конфиденциальность или находился под соответствующим установленным законом обязательством конфиденциальности;
- внедрить соответствующие технические и организационные меры для надлежащей защиты Персональных данных Клиента с учетом характера Персональных данных Клиента, которые должны быть защищены, и риска ущерба, который может возникнуть в результате любого Нарушения безопасности (как определено ниже), как указано в Соглашение о предоставлении услуг или соответствующие альтернативные меры и, как минимум, меры, изложенные в Приложении;
- незамедлительно информировать Клиента о любых запросах субъектов данных в соответствии с Законом о защите данных, а также о запросах регулирующих или правоохранительных органов, касающихся Персональных данных Клиента. Поставщик услуг может подтвердить каждый запрос доступа к данным. В случае согласования Поставщик услуг может за счет Клиента ответить на запрос доступа к теме от имени Клиента;
- за счет Клиента, предоставлять такую помощь, которую Клиент может разумно потребовать для обеспечения соблюдения Клиентом Закона о защите данных в отношении безопасности данных, уведомлений о нарушениях данных, оценок воздействия на защиту данных и предварительных консультаций с компетентными надзорными органами, отвечающими за вопросы конфиденциальности и защиты данных;
- , по выбору и за счет Клиента, удалить или вернуть все Персональные данные Клиента после окончания предоставления Услуг, а также удалить существующие копии всех Персональных данных Клиента, за исключением Персональных данных Клиента, заархивированных для непрерывности бизнеса и в целях аварийного восстановления, где это применимо, и анонимных личных данных клиента, сохраняемых для законных деловых целей.Поставщик услуг может удалить или уничтожить любые Персональные данные Клиента, которые больше не нужны для соблюдения настоящих Условий; и
- за счет Клиента, предоставлять Клиенту информацию, разумно необходимую для демонстрации соблюдения Поставщиком услуг настоящих Условий и позволяющих проводить аудиторские проверки независимой третьей стороной, по согласованию сторон.
- Клиент должен незамедлительно предоставить такую помощь, как Поставщик услуг может разумно потребовать для соблюдения своих обязательств по обеспечению конфиденциальности и безопасности данных в соответствии с настоящими Условиями.
- В отношении обработки Персональных данных Клиента в течение Срока, если иное не предусмотрено законом, Поставщик услуг соглашается:
- УВЕДОМЛЕНИЕ
- Поставщик услуг по запросу Клиента и за счет Клиента предоставит каждому субъекту данных стандартное уведомление о конфиденциальности Клиента, которое Клиент может разумно запрашивать время от времени в соответствии с Соглашением об обслуживании.
- СУБПРОЦЕССОРЫ
- Поставщик услуг будет привлекать любых субподрядчиков, участвующих в обработке Персональных данных Клиента (каждый из них — «Субпроцессор ») только с согласия Клиента, которое регулируется пунктом 7.2, настоящим.
- При привлечении Субпроцессора Поставщик услуг:
- проведет разумную проверку;
- заключить договор на условиях, насколько это практически возможно, таких же, как в настоящих Условиях, и который может включать в себя договорные положения для обеспечения адекватных гарантий в отношении обработки Персональных данных Клиента; и
- время от времени информирует Клиента о любых предполагаемых изменениях, касающихся добавления или замены Дополнительного процессора. Если Клиент возражает против любого такого изменения на разумных основаниях, то, действуя добросовестно, стороны будут работать вместе, чтобы разрешить такое возражение.
- ИНЦИДЕНТЫ БЕЗОПАСНОСТИ
- «Нарушение безопасности » означает нарушение безопасности, ведущее к случайному или незаконному уничтожению, потере, изменению, несанкционированному раскрытию или доступу к Персональным данным Клиента, переданным, хранящимся или иначе обработано.
- Поставщик услуг незамедлительно уведомит Клиента, если ему станет известно о любом Нарушении безопасности. По возможности, поставщик услуг будет предоставлять поэтапные уведомления.
- Поставщик услуг расследует Нарушение безопасности и примет разумные меры для выявления, предотвращения и смягчения последствий Нарушения безопасности, вызванного Поставщиком услуг. За счет Клиента Поставщик услуг предпримет такие дальнейшие действия, которые Клиент может обоснованно запросить в целях соблюдения Закона о защите данных.
- Клиент не может выпускать или публиковать какие-либо документы, сообщения, уведомления, пресс-релизы или отчеты о любом Нарушении безопасности без предварительного письменного согласия Поставщика услуг; в таком одобрении не должно быть необоснованно отказано.
- МЕЖДУНАРОДНАЯ ПЕРЕДАЧА ДАННЫХ
- Поставщик услуг гарантирует, что никакие Персональные данные Клиента не будут переданы ни одним из (9.1.1), ни (9.1.2) вариантов без явного предварительного письменного согласия Клиента, которое настоящим предоставляется с учетом пункта 9.2:
- Европейская экономическая зона; или
- на любой другой территории, на которой наложены ограничения на передачу Персональных данных Клиента за границу в соответствии с Законом о защите данных.
- За счет Клиента Поставщик услуг предоставит такую помощь, которую Клиент может разумно потребовать, чтобы гарантировать, что Договорные положения или другой применимый механизм передачи, такой как EU-US Privacy Shield Framework в отношении переводов между ЕС и США, существует для обеспечения надлежащего уровня защиты данных.
- Поставщик услуг гарантирует, что никакие Персональные данные Клиента не будут переданы ни одним из (9.1.1), ни (9.1.2) вариантов без явного предварительного письменного согласия Клиента, которое настоящим предоставляется с учетом пункта 9.2:
- РАЗНОЕ
- Пункт и другие заголовки в настоящих Условиях предназначены только для удобства ссылки и не должны составлять часть или иным образом влиять на значение или толкование настоящих Условий.
- В соответствии с пунктом 3 ответственность любой из сторон в соответствии с настоящими Условиями подлежит исключениям и ограничениям ответственности в соответствии с Соглашением о предоставлении услуг.
- Ничто в настоящих Условиях не исключает и не ограничивает ответственность любой из сторон, которая не может быть ограничена или исключена применимым законодательством.В соответствии с предыдущим предложением, (i) настоящие Условия и Соглашение об оказании услуг составляют полное соглашение между сторонами, касающееся обработки Персональных данных Клиента в рамках Услуг, и заменяют собой все предыдущие соглашения, договоренности, переговоры и обсуждения сторон, касающихся к его предмету; и (ii) при заключении настоящих Условий ни одна из сторон не полагалась, и ни одна из сторон не будет иметь никаких прав или средств правовой защиты на основании каких-либо заявлений, заявлений или гарантий, сделанных по небрежности или невиновности, за исключением тех, которые прямо изложены в настоящих Условиях.
- Клиент должен оплатить Поставщику услуг в течение 15 дней с даты выставления счета-фактуры любые расходы и расходы, включая, помимо прочего, разумные гонорары адвокатам и стоимость подготовки и отправки корреспонденции, понесенные Поставщиком услуг и / или его Аффилированными лицами в связи с выполнением обязанностей в Расходы Клиента в соответствии с настоящими Условиями.
- Если Клиент указывает, что Услуги больше не могут быть предоставлены в соответствии с Соглашением об оказании услуг, как это предусмотрено Поставщиком услуг, из-за запроса Клиента, полностью или частично, приостановить или прекратить действие любого контракта с Субпроцессором, приостановить или прекратить любую передачу Персональных данных Клиента, уничтожить или вернуть Клиенту все Персональные данные Клиента или приостановить или прекратить доступ к Персональным данным Клиента или аналогичный запрос, Поставщик услуг имеет право расторгнуть Соглашение о предоставлении услуг без каких-либо обязательств в любое время с немедленное или отсроченное вступление в силу путем письменного уведомления Клиента. После расторжения Соглашения о предоставлении услуг Поставщиком услуг или Клиентом по причинам, связанным с настоящими Условиями или соблюдением Закона о защите данных, все сборы за услуги, расходы и другие платежи в соответствии с Соглашением о предоставлении услуг должны быть немедленно уплачены Клиентом Поставщику услуг, рассчитанные по если Соглашение об оказании услуг было расторгнуто на законных основаниях для удобства Клиента в соответствии с его условиями.
- Все уведомления о расторжении договора или нарушении должны быть на английском языке в письменной форме и адресованы основному контактному лицу или юридическому отделу другой стороны.Уведомление будет рассматриваться как полученное при получении, что подтверждается действующей квитанцией или электронным журналом. Почтовые уведомления будут считаться полученными через 48 часов с даты отправки заказным письмом.
- Положения настоящих Условий являются отдельными. Если какая-либо фраза, пункт или положение являются недействительными или не имеющими исковой силы полностью или частично, такая недействительность или неисполнимость затрагивает только такую фразу, пункт или положение, а остальная часть настоящих Условий остается в полной силе.
- Любая из сторон может передать свои права и / или обязанности по настоящим Условиям своему правопреемнику в результате слияния, приобретения, продажи, реорганизации или ликвидации.
- Настоящие Условия регулируются английским законодательством, и стороны подчиняются исключительной юрисдикции английских судов в отношении любого спора (договорного или внедоговорного), касающегося настоящих Условий, за исключением того, что любая из сторон может обратиться в любой суд за судебным запретом или другим помощь для защиты своей собственности, прав интеллектуальной собственности или конфиденциальной информации.
 В соответствии с пунктом 2.2 сюда могут входить личные данные Партнерской программы Клиента.
В соответствии с пунктом 2.2 сюда могут входить личные данные Партнерской программы Клиента.

 Клиент гарантирует и постоянно заявляет, что его инструкции не приведут к нарушению Закона Поставщиком услуг;
Клиент гарантирует и постоянно заявляет, что его инструкции не приведут к нарушению Закона Поставщиком услуг; Поставщик услуг может подтвердить каждый запрос доступа к данным. В случае согласования Поставщик услуг может за счет Клиента ответить на запрос доступа к теме от имени Клиента;
Поставщик услуг может подтвердить каждый запрос доступа к данным. В случае согласования Поставщик услуг может за счет Клиента ответить на запрос доступа к теме от имени Клиента;
 Если Клиент возражает против любого такого изменения на разумных основаниях, то, действуя добросовестно, стороны будут работать вместе, чтобы разрешить такое возражение.
Если Клиент возражает против любого такого изменения на разумных основаниях, то, действуя добросовестно, стороны будут работать вместе, чтобы разрешить такое возражение.


 После расторжения Соглашения о предоставлении услуг Поставщиком услуг или Клиентом по причинам, связанным с настоящими Условиями или соблюдением Закона о защите данных, все сборы за услуги, расходы и другие платежи в соответствии с Соглашением о предоставлении услуг должны быть немедленно уплачены Клиентом Поставщику услуг, рассчитанные по если Соглашение об оказании услуг было расторгнуто на законных основаниях для удобства Клиента в соответствии с его условиями.
После расторжения Соглашения о предоставлении услуг Поставщиком услуг или Клиентом по причинам, связанным с настоящими Условиями или соблюдением Закона о защите данных, все сборы за услуги, расходы и другие платежи в соответствии с Соглашением о предоставлении услуг должны быть немедленно уплачены Клиентом Поставщику услуг, рассчитанные по если Соглашение об оказании услуг было расторгнуто на законных основаниях для удобства Клиента в соответствии с его условиями.
ПРИЛОЖЕНИЕ — Меры безопасности
Поставщик услуг должен принять следующие минимальные меры, если это применимо.
- поддерживать сертификацию ISO 27001: 2013
- межсетевые экраны последнего поколения
- минимальные системные привилегии управления доступом пользователей с идентификаторами пользователей и паролями с ограниченным сроком службы, где это необходимо
- ограниченный удаленный доступ и многофакторная аутентификация для удаленного доступа
- реальный- временная защита антивирусное, антивирусное и антишпионское программное обеспечение
- соблюдение инструкций производителя оборудования и программного обеспечения
- разделение данных в зависимости от клиента и цели, где необходимо
- регулярные обновления программного обеспечения
- безопасное удаление данных со списанных устройств
- 256 бит шифрование портативных устройств хранения данных и шифрование передаваемых личных данных
- системы обнаружения и предотвращения вторжений;
- резервное копирование данных с регулярным тестированием
- процедуры обеспечения непрерывности бизнеса и аварийного восстановления
- проверка персонала
- контроль физического доступа с минимальными привилегиями
- соглашения о неразглашении информации для персонала
- обучение персонала вопросам конфиденциальности
Обработка идиом учащимися уровня 2 английского языка на JSTOR
В этом исследовании изучались стратегии онлайн-обработки, используемые выборкой людей, не являющихся носителями английского языка, которых просили указать значения выбранных распространенных идиом, представленных в письменном контексте. Данные были собраны с помощью процедуры «подумай вслух»: участников просили озвучивать свои мысли по мере того, как они приходили к значениям идиом. Анализ показал, что большинство участников использовали эвристический подход к пониманию идиом, используя различные стратегии методом проб и ошибок, чтобы найти значения идиом. Модели усвоения идиомы L1 плохо подходят для понимания идиом пользователями L2. Включены некоторые педагогические предложения, основанные на результатах исследования.
Данные были собраны с помощью процедуры «подумай вслух»: участников просили озвучивать свои мысли по мере того, как они приходили к значениям идиом. Анализ показал, что большинство участников использовали эвристический подход к пониманию идиом, используя различные стратегии методом проб и ошибок, чтобы найти значения идиом. Модели усвоения идиомы L1 плохо подходят для понимания идиом пользователями L2. Включены некоторые педагогические предложения, основанные на результатах исследования.
TESOL Quarterly (TQ) — одно из самых уважаемых изданий в области преподавания второго и иностранного языков, с ежегодным уровнем принятия 8% всех статей, поданных на рассмотрение. Этот научный журнал служит форумом для исследователей, лингвистов и учителей. Как рецензируемый журнал, TQ специализируется в первую очередь на связи теории с практикой и решении практических вопросов преподавателей английского языка. Участники влияют на развитие профессии, объединяя исследования, научный дискурс и практику. Приблизительно 3600 членов TESOL и 1700 академических учреждений подписываются на TQ. Каждый сентябрь TQ выпускает специальный выпуск по актуальной актуальной теме. В сентябре 2007 года TQ сосредоточится на языковой политике и TESOL: перспективы из практики.
Приблизительно 3600 членов TESOL и 1700 академических учреждений подписываются на TQ. Каждый сентябрь TQ выпускает специальный выпуск по актуальной актуальной теме. В сентябре 2007 года TQ сосредоточится на языковой политике и TESOL: перспективы из практики.
TESOL — от преподавателей английского до говорящих на других языках — это аббревиатура, обозначающая профессиональную ассоциацию, профессию, и само поле. Штаб-квартира TESOL находится в Александрии, штат Вирджиния, США, и насчитывает более 13 500 членов из 140 стран.Его членство — это разнообразный состав учителей, исследователей, администраторов, составителей материалов и разработчиков учебных программ, чьи основные основное внимание уделяется улучшению изучения английского языка, будь то английский как второй язык (ESL) или английский как иностранный язык (EFL). Миссия TESOL — обеспечить высокое качество преподавания английского языка для носителей других языков.
Важность обработки естественного языка для неанглийских языков
Обработка естественного языка (NLP) становится все более популярной и играет жизненно важную роль во многих системах — от анализа резюме для приема на работу до автоматизированных телефонных служб. Вы также можете найти его в широко используемых технологиях, таких как чат-боты, виртуальные помощники и современные средства обнаружения спама. Однако развитие и внедрение технологии НЛП не так справедливо, как может показаться.
Вы также можете найти его в широко используемых технологиях, таких как чат-боты, виртуальные помощники и современные средства обнаружения спама. Однако развитие и внедрение технологии НЛП не так справедливо, как может показаться.
Для сравнения, хотя во всем мире говорят на более чем 7000 языках, подавляющее большинство процессов НЛП усиливают семь ключевых языков: английский, китайский, урду, фарси, арабский, французский и испанский.
Даже среди этих семи языков подавляющее большинство технологических достижений было достигнуто в англоязычных системах НЛП.Например, оптическое распознавание символов (OCR) все еще ограничено для языков, отличных от английского. И любой, кто использовал онлайн-сервис автоматического перевода, знает о серьезных ограничениях, если вы выходите за рамки ключевых языков, упомянутых выше.
Как разрабатываются конвейеры NLP?
Чтобы понять языковое неравенство в НЛП, полезно сначала понять, как эти системы разрабатываются. Типичный конвейер начинается со сбора и маркировки данных. Здесь важен большой набор данных, поскольку данные потребуются как для обучения, так и для тестирования алгоритма.
Типичный конвейер начинается со сбора и маркировки данных. Здесь важен большой набор данных, поскольку данные потребуются как для обучения, так и для тестирования алгоритма.
Когда конвейер разрабатывается для языка с небольшим количеством доступных данных, полезно иметь сильные шаблоны внутри языка. Небольшие наборы данных могут быть дополнены такими методами, как замена синонимов для упрощения языка, обратный перевод для создания предложений с аналогичной формулировкой для увеличения набора данных и замена слов другими связанными частями речи.
Языковые данные также требуют значительной очистки. Когда используется не английский язык со специальными символами, например китайский, обычно требуется правильная нормализация Unicode.Это позволяет преобразовать текст в двоичную форму, которая распознается всеми компьютерными системами, что снижает риск ошибок обработки. Эта проблема усиливается для таких языков, как хорватский, которые в значительной степени полагаются на ударение для изменения значения слова. Например, в хорватском языке один ударение может превратить положительное слово в отрицательное. Следовательно, эти термины необходимо кодировать вручную, чтобы обеспечить надежный набор данных.
Например, в хорватском языке один ударение может превратить положительное слово в отрицательное. Следовательно, эти термины необходимо кодировать вручную, чтобы обеспечить надежный набор данных.
Наконец, набор данных можно разделить на части для обучения и тестирования и отправить через процесс машинного обучения для разработки, моделирования, оценки и уточнения функций.
Исходное изображение, представленное на сайте Towards Data Science. Одним из широко используемых инструментов НЛП является двунаправленный кодировщик представлений от преобразователей (BERT) от Google, который призван разработать «современную» модель за 30 минут с использованием единственного блока обработки тензора. На их странице GitHub сообщается, что поддерживаются 100 лучших языков с самыми большими базами данных Википедии, но фактическая оценка и уточнение системы были выполнены только на 15 языках. Хотя технически BERT поддерживает больше языков, более низкий уровень точности и отсутствие надлежащего тестирования ограничивают применимость этой технологии. Другие системы NLP, такие как Word2Vec и Natural Language Toolkit (NLTK), имеют аналогичные ограничения.
Другие системы NLP, такие как Word2Vec и Natural Language Toolkit (NLTK), имеют аналогичные ограничения.
Таким образом, конвейер НЛП представляет собой проблему для менее популярных языков. Наборы данных меньше, они часто требуют работы по расширению, а процесс очистки требует времени и усилий. Чем меньше у вас доступа к ресурсам на родном языке, тем меньше данных доступно при построении конвейера НЛП. Это делает барьер для входа на менее популярные языки очень высоким, а во многих случаях и слишком высоким.
Важность разнообразной языковой поддержки в НЛП
Существует три всеобъемлющих точки зрения, которые поддерживают расширение НЛП:
- Усиление социальных проблем
- Нормативные предубеждения
- Расширение языка для улучшения технологии машинного обучения
Давайте рассмотрите каждый более подробно:
Укрепление социальных недостатков
С социальной точки зрения важно помнить, что технология доступна только тогда, когда ее инструменты доступны на вашем языке. На базовом уровне отсутствие технологии проверки орфографии мешает тем, кто говорит и пишет на менее распространенных языках. Это несоответствие поднимается вверх по технологической цепочке.
На базовом уровне отсутствие технологии проверки орфографии мешает тем, кто говорит и пишет на менее распространенных языках. Это несоответствие поднимается вверх по технологической цепочке.
Более того, психологические исследования показали, что язык, на котором вы говорите, влияет на ваше мышление. Встроенные языковые предпочтения в системах, управляющих Интернетом, по своей сути включают общественные нормы языков вождения.
Дело в том, что поддерживаемые системы продолжают развиваться, в то время как сложно вводить новые аспекты в глубоко укоренившуюся программу.Это означает, что по мере того, как НЛП продолжает развиваться, не привнося разнообразных языков, будет сложнее включить их в будущем, что поставит под угрозу глобальное разнообразие языков.
Нормативные предубеждения
Английский и смежные с английским языки не являются репрезентативными для других мировых языков, поскольку они имеют уникальные грамматические структуры, которые не характерны для многих языков. Однако, поддерживая в основном английский язык, Интернет и другие технологии постепенно рассматривают английский как нормальный язык по умолчанию.
Однако, поддерживая в основном английский язык, Интернет и другие технологии постепенно рассматривают английский как нормальный язык по умолчанию.
Поскольку относительно агностическая система обучается английскому языку, она изучает нормы и системы конкретного языка, а также все культурные последствия, связанные с этим ограничением. Этот односторонний подход будет становиться все более очевидным по мере того, как НЛП будет применяться к более интеллектуальным процессам, имеющим международную аудиторию.
Расширение языка для улучшения технологии машинного обучения
Когда мы применяем методы машинного обучения лишь к небольшому количеству языков, мы программируем неявное смещение в системах.Поскольку машинное обучение и НЛП продолжают развиваться, поддерживая лишь несколько языков, мы не только усложняем внедрение новых языков, но и рискуем сделать это принципиально невозможным.
Например, реализация токенизации подслов очень плохо работает на языках с дублированием, что характерно для многих международных языков, таких как африкаанс, ирландский, пенджаби и армянский.
Языки также имеют различные нормы порядка слов, которые имеют тенденцию ставить в тупик общие нейронные модели, используемые в основанном на английском языке НЛП.
Что можно сделать?
В нынешнем дискурсе вокруг НЛП, когда произносятся слова «естественный язык», общее предположение состоит в том, что исследователь работает с англоязычной базой данных. Чтобы вырваться из этой модели и повысить осведомленность о международных системах, мы должны прежде всего всегда обращаться к разрабатываемой языковой системе. Идея всегда указывать язык, над которым работает исследователь, в просторечии называется правилом Бендера.
Простого осознания вопроса, конечно, недостаточно.Тем не менее, осознание проблемы может помочь в разработке более широко применимых инструментов.
Если вы хотите добавить больше языков в конвейер НЛП, важно также учитывать размер набора данных. Если вы создаете новый набор данных, значительную часть вашего бюджета следует потратить на создание набора данных на другом языке. Конечно, дополнительные исследования по оптимизации текущих программ очистки и аннотаций на других языках также жизненно важны для распространения технологий НЛП по всему миру.
Конечно, дополнительные исследования по оптимизации текущих программ очистки и аннотаций на других языках также жизненно важны для распространения технологий НЛП по всему миру.
Не забудьте проверить соответствующие ресурсы ниже, чтобы найти больше технических статей, и подпишитесь на информационный бюллетень Lionbridge AI, чтобы получать интервью и статьи, доставляемые прямо на ваш почтовый ящик.
Начальные навыки обработки текстов | Английская композиция I
Большую часть писем, которые вы пишете для колледжа, нужно будет печатать на машинке и часто отправлять в электронном виде. Освоение основ работы с инструментами обработки текста сделает этот процесс намного более комфортным.
Самая популярная программа для обработки текстов — Microsoft Word, входящая в состав Microsoft Office Suite.Эта программа доступна в большинстве компьютерных лабораторий колледжей, и вы часто можете приобрести ее по сниженной цене в книжном магазине колледжа.
Некоторые классы явно потребуют от вас использовать Microsoft Word для работы в классе. В противном случае вы можете использовать любую программу, какую захотите. Еще два широко используемых примера — это страницы Apple и Google Документы.
В противном случае вы можете использовать любую программу, какую захотите. Еще два широко используемых примера — это страницы Apple и Google Документы.
В видеороликах в этом разделе используется Microsoft Word 2016 . Если вы используете другую программу обработки текста (или другую версию Word), определенные инструменты могут появиться в разных местах, но вы все равно сможете выполнять те же действия.
Знакомство с Word
Давайте начнем с обзора программы в целом и того, на что она способна.
Создание и открытие документов
Теперь давайте посмотрим, как приступить к работе с новым файлом документа.
Сохранение и отправка
Всегда важная функция «Сохранить» станет вашим новым лучшим другом в колледже.
Основы работы с текстом
Вырезание, копирование, вставка и удаление рассматриваются здесь.«Найти и заменить» — это инструмент, который особенно пригодится при редактировании документов.
Форматирование текста
Создание привлекательного внешнего вида документа — одна из самых увлекательных частей работы с текстовым редактором. В этом видео демонстрируются быстрые способы изменить внешний вид текста.
Макет страницы
У вашего профессора могут быть конкретные инструкции о том, как он хочет, чтобы вы форматировали документы, которые вы пишете для ее класса. В таком случае узнайте, как изменить настройки макета и форматирования здесь.
В таком случае узнайте, как изменить настройки макета и форматирования здесь.
Печать
Наконец, мы заканчиваем очень важным шагом — получением бумажной копии вашей работы.
Проблемы обработки текста с языками, отличными от английского | Тена Белинич | KrakenSystems
Английский язык — язык номер один в Интернете. В Интернете доступно множество аннотированных наборов данных и различных пакетов, таких как превосходный NLTK, простой TextBlob или самый быстрый синтаксический синтаксический анализатор spaCy. Фактически, часть речевых тегов в предложениях на английском языке сегодня считается закрытой проблемой. За последние 11 лет он улучшился всего на 1,04% — до с высокой точностью 97,50% (подробнее см. В статьях Агича и др. (2013) и Маннига и др. (2011)). Кроме того, распознавание именованных сущностей (или определение слов и групп слов, таких как понятия, такие как люди, местоположения, организации, объекты и т. Д.) Обычно имеет точность более 90%, тогда как автоматическое суммирование текста достигает точности более 88%. Несмотря на все это, нельзя сказать, что обработка английских предложений всегда проходит гладко и безболезненно, наверняка в этом есть свои проблемы.Но вы можете справиться с этими проблемами быстро, поскольку есть большое сообщество, которое решает те же проблемы и делится результатами и опытом.
Фактически, часть речевых тегов в предложениях на английском языке сегодня считается закрытой проблемой. За последние 11 лет он улучшился всего на 1,04% — до с высокой точностью 97,50% (подробнее см. В статьях Агича и др. (2013) и Маннига и др. (2011)). Кроме того, распознавание именованных сущностей (или определение слов и групп слов, таких как понятия, такие как люди, местоположения, организации, объекты и т. Д.) Обычно имеет точность более 90%, тогда как автоматическое суммирование текста достигает точности более 88%. Несмотря на все это, нельзя сказать, что обработка английских предложений всегда проходит гладко и безболезненно, наверняка в этом есть свои проблемы.Но вы можете справиться с этими проблемами быстро, поскольку есть большое сообщество, которое решает те же проблемы и делится результатами и опытом.
Напротив, когда вы обрабатываете язык с более богатой морфологией и более гибким порядком слов, вам нужно больше предварительной обработки, немного больше творчества и гораздо больше времени для достижения такой же значительной точности, как и для английского языка. Чтобы проиллюстрировать проблемы с таким языком, мы рассмотрим хорватский язык (но тот же подход может быть использован для любых других языков — словацкого, финского, турецкого и т. Д.).Поскольку он менее распространен (по сравнению с английским, немецким, испанским или французским), нецелесообразно разрабатывать новый инструмент обработки текста для каждой из его языковых разновидностей. Это займет слишком много времени и данных. Вместо этого лучше найти способ стандартизировать все слова в наблюдаемом тексте.
Чтобы проиллюстрировать проблемы с таким языком, мы рассмотрим хорватский язык (но тот же подход может быть использован для любых других языков — словацкого, финского, турецкого и т. Д.).Поскольку он менее распространен (по сравнению с английским, немецким, испанским или французским), нецелесообразно разрабатывать новый инструмент обработки текста для каждой из его языковых разновидностей. Это займет слишком много времени и данных. Вместо этого лучше найти способ стандартизировать все слова в наблюдаемом тексте.
Хорватский — очень флективный язык. означает, что местоимения, существительные, прилагательные и даже некоторые числительные склоняются, в то время как глаголы спрягаются для обозначения лица и времени.Глаголы могут быть совершенными (завершенное действие) или несовершенными (неполное или повторяющееся действие) с разными приставками. Это язык с ограниченными лингвистическими ресурсами, и в Интернете доступно всего несколько аннотированных баз данных. Итак, в большинстве случаев вы должны аннотировать десятки тысяч примеров данных для создания полезной нейронной сети для обработки текста!
Итак, в большинстве случаев вы должны аннотировать десятки тысяч примеров данных для создания полезной нейронной сети для обработки текста!
Кроме того, повседневное онлайн-общение увеличивает сложность языковой обработки.Люди склонны использовать разговорные выражения или сокращения и иностранные слова. Они не соблюдают грамматические или орфографические нормы и не стараются исправить орфографические ошибки. Например, в твитах или комментариях в социальных сетях люди часто пропускают диакритические знаки. Если вы попытаетесь прочитать такой текст, у вас не возникнет проблем, и вы легко его поймете; но для компьютера такой текст становится проблемой для обработки. Он определяет эти «новые» слова как неоднозначные или неизвестные формы и не может автоматически связать их с их диакритической формой.
Например, на хорватском языке č и ć становятся c , š становится s , ž становится z , а đ становится d или 909558 dj люди даже используют заменители, такие как ch или sh для č и š . Самая большая проблема в том, что без диакритических знаков слова с разным значением становятся равными, например, kos (черный дрозд) и koš (корзина), zao (зло) и žao (извините) или voda (вода ) и vođa (лидер).Неправильное значение одного слова в предложении может полностью изменить его тональность. Таким образом, одним из хороших этапов предварительной обработки является восстановление диакритических знаков , которое может быть выполнено на уровне букв или слов.
Самая большая проблема в том, что без диакритических знаков слова с разным значением становятся равными, например, kos (черный дрозд) и koš (корзина), zao (зло) и žao (извините) или voda (вода ) и vođa (лидер).Неправильное значение одного слова в предложении может полностью изменить его тональность. Таким образом, одним из хороших этапов предварительной обработки является восстановление диакритических знаков , которое может быть выполнено на уровне букв или слов.
Подход на уровне слов дает лучшие результаты, но требует большого словарного запаса, который обычно не охватывает нестандартные словоформы. Для хорватского языка есть отличный инструмент для восстановления диакритических знаков ReLDI с доступной статьей, описывающей подход на уровне слов.Также доступны словацкие диакры и вьетнамские реставрационные знаки. Асахия и его сотрудники из Кембриджского университета создали превосходный обзор восстановления диакритики в системах письма абджад и алфавит. Авторы объяснили разные подходы для разных языков и перечислили прошлые достижения, поэтому этот обзор является хорошей отправной точкой.
Авторы объяснили разные подходы для разных языков и перечислили прошлые достижения, поэтому этот обзор является хорошей отправной точкой.
Пример восстановления диакритики с помощью ReLDI. Все диакритические знаки восстановлены, и слово sto (сто) теперь имеет значение što (что), что является настоящим значением этого слова.
из reldi.restorer import DiacriticRestorer
dr = DiacriticRestorer ('hr') dr.authorize ('my_username', 'my_password') предложение = "Osim sto rjesava zlocine, Inspektor Skrga Je istovremeno zalviuficias ias ujenvozaljubljasi fatalnu zavodnicu, barsku pjevacicu Andelu. "dr.restore (приговор)
Вывод:
" Osim što rješava zločine, инспектор Škrga je istovremeno zaljubljen u dvije zevojkujku.«
Еще один полезный шаг предварительной обработки — , выделение корня . Как объяснялось в предыдущей статье , моя , , выделение корня удаляет суффиксы слов. Вы можете создать свой собственный стеммер, следуя стандартным грамматическим правилам, определенным вашим языком, с использованием обычных выражения, eq с пакетом python re (см. пример ниже). Со списком таких правил вы можете добиться большей точности, поскольку разные формы одного и того же слова стали сопоставимыми и похожими.
Вы можете создать свой собственный стеммер, следуя стандартным грамматическим правилам, определенным вашим языком, с использованием обычных выражения, eq с пакетом python re (см. пример ниже). Со списком таких правил вы можете добиться большей точности, поскольку разные формы одного и того же слова стали сопоставимыми и похожими.
Вот пример объединения с пакетом re для хорватского языка. Мы удаляем все суффиксы, такие как jući или smo , из глаголов, основа которых заканчивается на ava , eva , iva или uva . Итак, это настраиваемое правило для создания основы из таких глаголов, как spavati , pjevati , plivati или čuvati . Как видите, различные формы глагола rješavati (решение) становятся одинаковыми в этом коротком алгоритме.
импортный текст, суффикс = ".('+ стебель +') ('+ суффикс + r') $ ') words = ["ржешавах", "ржешаваючи", "ржешавасмо", "ржешавао", "спавала", "пьевай", "чуваймо", "плейте "] stem = [(rule. match (word.decode ('utf8'))). group (1) для слова в словах] print (stem)  match (word.decode ('utf8'))). group (1) для слова в словах] print (stem)
match (word.decode ('utf8'))). group (1) для слова в словах] print (stem) Вывод:
[" rješava "," rješava " , «rješava», «rješava», «spava», «pjeva», «čuva», «pliva»]
В хорватском языке даже такая простая вещь, как , список стоп-слов может увеличиваться до огромных размеров , если вы хотите включать все разнообразие, а не ограничивать набор данных.Чтобы объяснить, стоп-слова — это слова, которые не несут никакой полезной информации при обработке естественного языка, и они обычно отфильтровываются до или после обработки. Они относятся к наиболее «распространенным» словам, таким как я, она, by, about, here и т. Д. Удаление таких слов в контексте анализа тональности может легко повысить вашу точность на 5%!
Пример облака слов для стоп-слов на английском и хорватском языках. Размеры облаков такие же, но количество стоп-слов на хорватском языке (или плотность облаков) в несколько раз превышает количество стоп-слов на английском языке.
Вы также можете создать алгоритм лемматизации и соединить разные слова с одинаковым значением, хотя это намного сложнее и требует много времени, чем простое выделение слов. Это применимо во всем диапазоне процедур — от простого текстового поиска до сложного парсинга. Существует два доминирующих подхода к лемматизации: алгоритмический (основанный на правилах и реализованный как FSA, конечные автоматы) и реляционный (управляемый данными и реализованный с помощью баз данных).Первый очень сложный с системой правил для различных словоформ леммы, его сложно создать, но он подходит для неизвестных слов. Второй подход работает со списком всех возможных форм каждой леммы, он относительно прост, но требует огромного словарного запаса и по-прежнему не может обрабатывать неизвестные слова. Поэтому перед лемматизацией текста действительно полезно исправить орфографические и письменные ошибки.
Пример лемматизации для хорватского языка с помощью ReLDI. Существительные и местоимения были переведены в форму именительного падежа единственного числа, а глаголы были заменены на форму инфинитива.
Существительные и местоимения были переведены в форму именительного падежа единственного числа, а глаголы были заменены на форму инфинитива.
from reldi.tagger import Tagger
t = Tagger ('hr')
t.authorize ('my_username', 'my_password') предложение = "Детективные носки помаже, нанюшити smrdljive ribe и privesti ih licu pravde." T. tagLemmatise (предложение)
Вывод:
["škrga", "Detektiv", "nos", "pomoć", "on", "njušiti", "smrad", "riba", "i", " privesti "," oni "," lice "," pravda "]
Важность обработки естественного языка для неанглийских языков | Мехрназ Сиавоши
Обработка естественного языка (NLP) становится все более популярной и играет жизненно важную роль во многих системах, от анализа резюме для приема на работу до автоматизированных телефонных служб.Вы также можете найти его в широко используемых технологиях, таких как чат-боты, виртуальные помощники и современные средства обнаружения спама. Однако развитие и внедрение технологии НЛП не так справедливо, как может показаться.
Для сравнения, хотя во всем мире говорят на более чем 7000 языках, подавляющее большинство процессов НЛП усиливают семь ключевых языков: английский, китайский, урду, фарси, арабский, французский и испанский.
Даже среди этих семи языков подавляющее большинство технологических достижений было достигнуто в англоязычных системах НЛП.Например, оптическое распознавание символов (OCR) все еще ограничено для языков, отличных от английского. И любой, кто использовал онлайн-сервис автоматического перевода, знает о серьезных ограничениях, если вы выходите за рамки ключевых языков, упомянутых выше.
Чтобы понять языковое неравенство в НЛП, полезно сначала понять, как эти системы разрабатываются. Типичный конвейер начинается со сбора и маркировки данных. Здесь важен большой набор данных, поскольку данные потребуются как для обучения, так и для тестирования алгоритма.
Когда конвейер разрабатывается для языка с небольшим количеством доступных данных, полезно иметь сильные шаблоны внутри языка.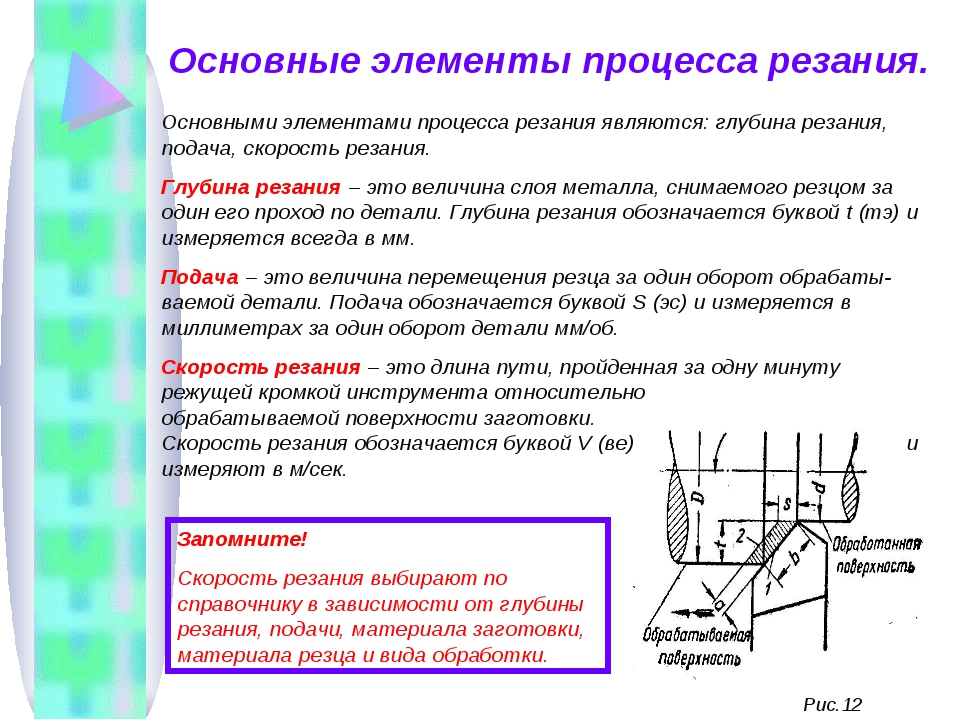 Небольшие наборы данных могут быть дополнены такими методами, как замена синонимов для упрощения языка, обратный перевод для создания предложений с аналогичной формулировкой для увеличения набора данных и замена слов другими связанными частями речи.
Небольшие наборы данных могут быть дополнены такими методами, как замена синонимов для упрощения языка, обратный перевод для создания предложений с аналогичной формулировкой для увеличения набора данных и замена слов другими связанными частями речи.
Языковые данные также требуют значительной очистки. Когда используется не английский язык со специальными символами, например китайский, обычно требуется правильная нормализация Unicode.Это позволяет преобразовать текст в двоичную форму, которая распознается всеми компьютерными системами, что снижает риск ошибок обработки. Эта проблема усиливается для таких языков, как хорватский, которые в значительной степени полагаются на ударение для изменения значения слова. Например, в хорватском языке один ударение может превратить положительное слово в отрицательное. Следовательно, эти термины необходимо кодировать вручную, чтобы обеспечить надежный набор данных.
Наконец, набор данных можно разделить на части для обучения и тестирования и отправить через процесс машинного обучения для разработки, моделирования, оценки и уточнения функций.
Одним из наиболее часто используемых инструментов НЛП является двунаправленный кодировщик представлений от трансформаторов (BERT) от Google, который предназначен для разработки «современной» модели за 30 минут с использованием единственного блока обработки тензора. На их странице GitHub сообщается, что поддерживаются 100 лучших языков с самыми большими базами данных Википедии, но фактическая оценка и уточнение системы были выполнены только на 15 языках. Хотя технически BERT поддерживает больше языков, более низкий уровень точности и отсутствие надлежащего тестирования ограничивают применимость этой технологии.Другие системы NLP, такие как Word2Vec и Natural Language Toolkit (NLTK), имеют аналогичные ограничения.
Таким образом, конвейер НЛП представляет собой проблему для менее популярных языков. Наборы данных меньше, они часто требуют работы по расширению, а процесс очистки требует времени и усилий. Чем меньше у вас доступа к ресурсам на родном языке, тем меньше данных доступно при построении конвейера НЛП. Это делает барьер для входа на менее популярные языки очень высоким, а во многих случаях и слишком высоким.
Это делает барьер для входа на менее популярные языки очень высоким, а во многих случаях и слишком высоким.
Существует три всеобъемлющих точки зрения, которые поддерживают расширение НЛП:
- Усиление социальных проблем
- Нормативные предубеждения
- Расширение языка для улучшения технологии машинного обучения
Давайте рассмотрим каждую подробнее:
Со стороны общества В перспективе важно помнить, что технология доступна только в том случае, если ее инструменты доступны на вашем языке. На базовом уровне отсутствие технологии проверки орфографии мешает тем, кто говорит и пишет на менее распространенных языках.Это несоответствие поднимается вверх по технологической цепочке.
Более того, психологические исследования показали, что язык, на котором вы говорите, влияет на ваше мышление. Встроенные языковые предпочтения в системах, управляющих Интернетом, по своей сути включают общественные нормы языков вождения.
Дело в том, что поддерживаемые системы продолжают развиваться, в то время как сложно вводить новые аспекты в глубоко укоренившуюся программу.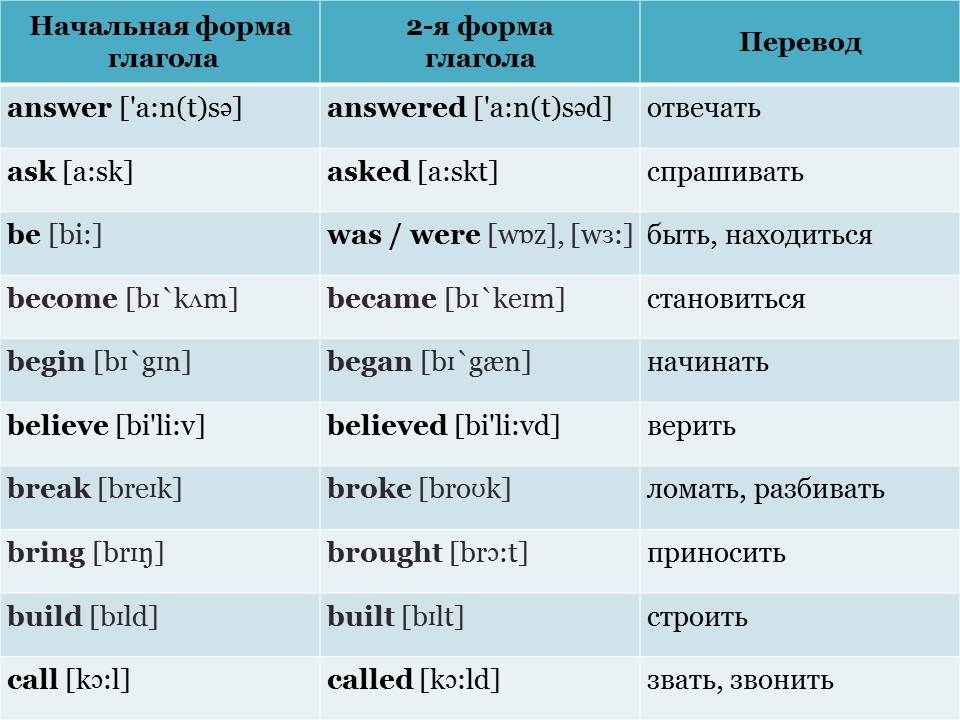 Это означает, что по мере того, как НЛП продолжает развиваться, не привнося разнообразных языков, будет сложнее включить их в будущем, что поставит под угрозу глобальное разнообразие языков.
Это означает, что по мере того, как НЛП продолжает развиваться, не привнося разнообразных языков, будет сложнее включить их в будущем, что поставит под угрозу глобальное разнообразие языков.
Английский и смежные с ним языки не являются репрезентативными для других мировых языков, поскольку они имеют уникальные грамматические структуры, которых нет у многих языков. Однако, поддерживая в основном английский язык, Интернет и другие технологии постепенно рассматривают английский как нормальный язык по умолчанию.
Поскольку относительно агностическая система обучается английскому языку, она изучает нормы и системы конкретного языка, а также все культурные последствия, связанные с этим ограничением.Этот односторонний подход будет становиться все более очевидным по мере того, как НЛП будет применяться к более интеллектуальным процессам, имеющим международную аудиторию.
© Ади Перетс, Pexels Когда мы применяем методы машинного обучения только к небольшому количеству языков, мы программируем неявную предвзятость в системах. Поскольку машинное обучение и НЛП продолжают развиваться, поддерживая лишь несколько языков, мы не только усложняем внедрение новых языков, но и рискуем сделать это принципиально невозможным.
Поскольку машинное обучение и НЛП продолжают развиваться, поддерживая лишь несколько языков, мы не только усложняем внедрение новых языков, но и рискуем сделать это принципиально невозможным.
Например, реализация токенизации подслов очень плохо работает на языках с дублированием, что характерно для многих международных языков, таких как африкаанс, ирландский, пенджаби и армянский.
Языки также имеют различные нормы порядка слов, которые имеют тенденцию ставить в тупик общие нейронные модели, используемые в основанном на английском языке НЛП.
В нынешнем дискурсе вокруг НЛП, когда произносятся слова «естественный язык», общее предположение состоит в том, что исследователь работает с англоязычной базой данных.Чтобы вырваться из этой модели и повысить осведомленность о международных системах, мы должны прежде всего всегда обращаться к разрабатываемой языковой системе. Идея всегда указывать язык, над которым работает исследователь, в просторечии называется правилом Бендера.