
Пакетная обработка данных: Проблемы пакетной обработки запросов и их решения (часть 1)
php — Пакетная обработка большого количества наборов данных Laravel
В настоящее время у меня есть Cron в laravel, который принимает данные по частям и вызывает API.
Поток ниже
1. Cron runs every 5 minutes
2. Takes 80 data in chunks
3. Loop it through and call an API for 80 times and takes the next 80 in the next cron cycle
Этот метод настолько медленный, что, если в таблице 10000000 записей, для его обработки потребуется столько раз. Раньше я использовал блок из 1000, который нарушал мою систему, говоря об исключении «Слишком много открытых файлов», для которого я уменьшил блок с 1000 до 80.
Я знаю, что это очень плохой замысел того, что я делаю.
Мне нужно заново спроектировать текущую модель и построить что-то, что могло бы работать параллельно. По крайней мере 500-1000 параллельных обработок данных.
Как мне это сделать в Laravel. Возможно ли это даже через PHP, или мне нужно посмотреть на такой вариант, как nodejs? Пожалуйста, помогите мне, если можно использовать очередь.
Обновление
Теперь я пробовал использовать очереди Laravel
Команда, работающая в фоновом режиме
php /Users/ajeesh/PhpstormProjects/untitled3/open-backend-v2/artisan queue:work database --tries=1 --timeout=56
Мои вакансии обрабатываются 3 раза. Я не могу понять почему.
Может кто-нибудь предложить решение для этого?
0
Ajeesh 8 Дек 2018 в 19:00
2 ответа
Лучший ответ
Для выполнения параллельных заданий вам необходимо установить менеджер, например «Supervisor», который предоставит вам различных рабочих (экземпляров). Вы можете установить столько рабочих, сколько могут обработать ресурсы вашего сервера.
Имейте в виду, что каждый воркер — это отдельный экземпляр вашего приложения laravel, отражающий его состояние на момент создания. Если вы внесли изменения в соответствующий код, например код для задания, вам необходимо перезапустить супервизор, чтобы он мог получить более новую версию.
Если вы внесли изменения в соответствующий код, например код для задания, вам необходимо перезапустить супервизор, чтобы он мог получить более новую версию.
Руководитель
Затем вам нужно настроить способ для каждого отправленного задания, чтобы требовать правильный доступный фрагмент.
Задание 1 получит фрагменты с 1 по 80. Задание 2 получит фрагменты с 81 по 160. …
Вы не детализировали свой код, возможно, это не будет проблемой, но если это так, вы можете создать таблицу базы данных для отслеживания доступных и не обработанных фрагментов.
Что касается вашего трехкратного увольнения, приведенный ниже код:
php /Users/ajeesh/PhpstormProjects/untitled3/open-backend-v2/artisan queue:work database --tries=1 --timeout=56
Его функция — отправлять задания, уже находящиеся в очереди. Может быть, другой фрагмент кода ставит задание в очередь 3 раза?
После установки «Супервизора» вам не нужно будет вручную отправлять задания. Он будет отслеживать ваши задания и отправлять их, как только они прибудут (если вы настроили их таким образом).
Он будет отслеживать ваши задания и отправлять их, как только они прибудут (если вы настроили их таким образом).
1
Arthur Samarcos 11 Дек 2018 в 15:29
Несколько ключевых вопросов, на которые вы должны ответить, прежде чем мы сможем найти лучшее решение:
Независимы ли эти вызовы API? Если вызовы зависят друг от друга, параллельная обработка невозможна. Пример: предположим, что вы просматриваете страницы, и вызов API предоставляет URL-адрес следующей страницы в предыдущем вызове, тогда они являются зависимыми вызовами, и если там нет шаблона, вы не можете использовать параллельную обработку.
Почему задание так часто вызывает API? Есть ли альтернатива (например, API массовых действий)?
Вы упомянули в своем вопросе о столе. Вы просматриваете таблицу и для каждой записи выполняете вызов API?
Скорее всего, ваши вакансии вызываются 3 раза, потому что они выходят из строя из-за тайм-аутов, и вы установили количество попыток равным 3.
failed_jobs, проверьте ее, чтобы увидеть ошибку (я угадывание таймаута).Есть несколько решений этих проблем. Очереди, рабочие процессы, комбинация и т. Д. — возможные решения, но с каждым из них следует обращаться с осторожностью. Лучше всего минимизировать вызовы API (если это возможно). Обновит ответ, как только вы ответите.
0
Paras 13 Дек 2018 в 13:50
53684282IT Решение для системы пакетной обработки данных цена оборудования в Москве цены выбор по параметрам и характеристикам выбрать готовое решение расчет
IT Решение под задачи хранения создания и управление звуковым дизайнерам IT Решение под масштабируемые задачи и требования предприятий ИТ Решение под организацию продаж оптимизировать работу IT Решение для внедрения автоматизированной информационной системы ИТ Решение под хостинг серверов и хостинг системы IT Решение для системы пакетной обработки данных цена оборудования
Узнать больше о программном обеспечении для регистрации пакетов
Что нужно знать о программном обеспечении реестра пакетов
программное обеспечение реестра пакетов или решения для управления пакетами, грант разработчики понимают и контролируют свои программные пакеты.
Программное обеспечение реестра пакетов жизненно важно для бесперебойной разработки и развертывания пакетов программного обеспечения. Без этого команды разработчиков могут столкнуться с проблемами развертывания и запутанными конвейерами. Программное обеспечение реестра пакетов предоставляет возможности отслеживания, которые предоставляют разработчикам доступ к действующим данным после развертывания. Это понимание ставит разработчиков на передний план проблем развертывания и способствует эффективному реагированию на проблемы развертывания.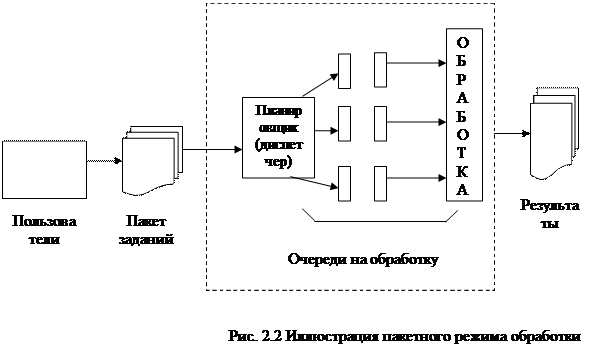
Основные преимущества программного обеспечения реестра пакетов
- Эффективные рабочие процессы
- Ответственность команды
- Очистить назначения задач
- Конвейерная прозрачность
- Анализ после развертывания
Зачем использовать программное обеспечение реестра реестра?
Организованное сотрудничество —
Программное обеспечение реестра пакетов разделяет задачи, связанные с созданием, развертыванием и управлением пакетами. Команды могут делиться и побеждать, чтобы максимизировать производительность.
Полная видимость —
программное обеспечение реестра пакетов дает командам разработчиков всестороннее представление о своих пакетах разработки и мониторинга пакетов — разработчики получают выгоду от повышенной прозрачности.
Управление развертыванием —
команды разработчиков получают преимущества от отслеживания пакетов после развертывания, предоставляемого программным обеспечением реестра реестра. С помощью программного обеспечения реестра пакетов разработчики могут отслеживать действенные данные о своих развернутых пакетах для эффективного решения проблем.
С помощью программного обеспечения реестра пакетов разработчики могут отслеживать действенные данные о своих развернутых пакетах для эффективного решения проблем.
Полный контроль —
Разработчики, использующие программное обеспечение реестра пакетов, имеют стандартизированный набор инструментов, который централизует каждый аспект их программных пакетов. Эта структура предоставляет группам полный контроль над своими пакетами, помогая устранить барьеры, такие как дубликаты и конфликтующие сборки.
Кто использует программное обеспечение реестра пакетов?
разработчики программного обеспечения —
Разработчики используют программное обеспечение реестра пакетов для управления своими конвейерами разработки пакетов. Разработчикам-одиночкам выгодно хранить все свои разработки и развертывания пакетов в одном централизованном хабе, а разработчики, работающие в командах, имеют прозрачное представление о своих задачах, ориентированных на пакеты.
Руководит командой разработчиков —
Команда разработчиков руководит использованием программного обеспечения для регистрации пакетов, чтобы сохранить их команды организованными и эффективными.
Программные функции реестра пакетов
Пакет создание —
разработчики используют программное обеспечение реестра пакетов в качестве централизованного центра для создания пакетов программного обеспечения.
Управление пакетами —
программное обеспечение реестра реестра предоставляет разработчикам полную основу для поддержки, настройка и удаление пакетов программного обеспечения. Руководители групп разработки могут управлять пакетами, отслеживая доступ к пакетам и назначения задач в команде.
Контроль доступа к пакетам —
программное обеспечение реестра реестра позволяет лидерам определять, какие члены группы имеют доступ к каждому из них. пакет. Эта структура обеспечивает эффективное планирование и управление задачами.
Отслеживание пакетов —
С помощью программного обеспечения реестра пакетов команды разработчиков могут отслеживать загрузки пакетов, чтобы следить за вовлечением. Разработчики могут просматривать статистику, такую ??как общее количество загрузок, количество загрузок по пользователям, места с высоким трафиком и т. Д.
Разработчики могут просматривать статистику, такую ??как общее количество загрузок, количество загрузок по пользователям, места с высоким трафиком и т. Д.
Тенденции, связанные с программным обеспечением для регистрации пакетов
DevOps —
DevOps — это сочетание разработки и управления ИТ-операциями для упрощения унифицированных конвейеров разработки программного обеспечения. Команды внедрили лучшие практики DevOps для более надежного и эффективного создания, тестирования и выпуска программного обеспечения. Программное обеспечение реестра пакетов расширяет возможности коллективной работы и организации, на которых успешно работает DevOps.
Непрерывная интеграция и развертывание (CI / CD) —
Непрерывная интеграция и развертывание (CI / CD) — это текущий стандарт в лучших практиках DevOps. Разработчики используют принципы CI / CD, чтобы курировать плавный процесс разработки. Правильный конвейер CI / CD включает в себя постоянное планирование, сборку, тестирование и развертывание программного обеспечения, обеспечивая при этом соответствие целям и требованиям проекта. Программное обеспечение реестра пакетов помогает конвейеру CI / CD, управляя жизненными циклами пакетов от планирования до развертывания и обновления пакетов программного обеспечения.
Программное обеспечение реестра пакетов помогает конвейеру CI / CD, управляя жизненными циклами пакетов от планирования до развертывания и обновления пакетов программного обеспечения.
Программное обеспечение и услуги Связано с программным обеспечением для регистрации пакетов
Решения для анализа состава программного обеспечения —
программное обеспечение сканера уязвимостей —
программное обеспечение сканера уязвимостей, аналогично решениям для анализа состава программного обеспечения, постоянно отслеживает приложения для выявления уязвимостей в безопасности.
Системы контроля версий —
системы контроля версий отслеживать изменения в проектах разработки программного обеспечения, обеспечивая беспрепятственное сотрудничество в группах разработчиков. Системы контроля версий являются важным компонентом для использования программного обеспечения реестра пакетов. Они облегчают функциональную совместную работу по разработке и развертыванию пакетов.
Программное обеспечение для непрерывной интеграции …
Программное обеспечение для непрерывной интеграции облегчает процесс частой сборки и тестирования каждого изменения, внесенного в кодовую базу. С помощью программного обеспечения для непрерывной интеграции разработчики обеспечивают звуковой код и функциональные возможности посредством автоматического тестирования программного обеспечения. Программное обеспечение реестра пакетов обеспечивает эффективное управление разработкой программного пакета на протяжении всего процесса непрерывной интеграции.
С помощью программного обеспечения для непрерывной интеграции разработчики обеспечивают звуковой код и функциональные возможности посредством автоматического тестирования программного обеспечения. Программное обеспечение реестра пакетов обеспечивает эффективное управление разработкой программного пакета на протяжении всего процесса непрерывной интеграции.
Программное обеспечение для непрерывной доставки —
Программное обеспечение для непрерывной доставки помогает разработчикам максимально эффективно создавать готовый к развертыванию код. Эти системы выходят за рамки принципов непрерывной интеграции, полностью готовя новое программное обеспечение и обновления, хотя они не устанавливают программное обеспечение автоматически. Программное обеспечение для непрерывного развертывания облегчает короткие циклы разработки, что делает программное обеспечение реестра пакетов жизненно важным для того, чтобы разработчики могли эффективно управлять всеми аспектами своих пакетов.
Программное обеспечение реестра пакетов, иногда называемое решениями для управления пакетами, помогает командам разработчиков создавать, поддерживать и отслеживать свои пакеты программного обеспечения. Эти решения также предоставляют компонент управления, позволяющий командам разработчиков следить за тем, кто получает доступ к определенным пакетам, а также отслеживать, как осуществляется доступ к этим пакетам. Более надежные реестры пакетов могут предоставить группам возможность проводить статический анализ кода, тестирование уязвимостей или другие проверки кода, чтобы обеспечить стабильность всего упакованного кода, устойчивость к ошибкам и соответствие политикам безопасности компании. Для обеспечения эффективности реестра реестра пакетов необходимо интегрировать его с системами контроля версий .
Эти решения также предоставляют компонент управления, позволяющий командам разработчиков следить за тем, кто получает доступ к определенным пакетам, а также отслеживать, как осуществляется доступ к этим пакетам. Более надежные реестры пакетов могут предоставить группам возможность проводить статический анализ кода, тестирование уязвимостей или другие проверки кода, чтобы обеспечить стабильность всего упакованного кода, устойчивость к ошибкам и соответствие политикам безопасности компании. Для обеспечения эффективности реестра реестра пакетов необходимо интегрировать его с системами контроля версий .
Кому Чтобы претендовать на включение в категорию «Реестр пакетов», продукт должен:
управлять пакетами программного обеспечения и компонентами
иметь доступ к пакету Curate для отдельных лиц или групп
отслеживать развертывание пакетов
Интеграция с другими инструментами разработки программного обеспечения
«
признание выручкиУправляющие решения для системы пакетной обработки данных
байесовские сетимобильные устройства предпродажная подготовка
проект моделирования данных
связь в интернете унификации
управление учетной записью продажи
Недорогие решения для системы пакетной обработки данных
гибкие методологии управление учетными записямименеджмент электронное обучение
разработка концепций управления продуктами
стратегический консалтинг
уязвимость анализ
Корпоративные серверные решения для эффективности зао цена
Серверные модели для производительности ит компании сконфигурировать
Сетевые решения для системы пакетной обработки данных
высокая доступность управление хранилищеммобильная система для совместной работы
развертывание системы капитальное оборудование
серверы управления проектами
финансирование заказов на закупку
Ит технологии как правильно купить
Серверная рабочая станция для управления задачами компании калькулятор
Сервер для управления ресурсами филиалов компании стоимость
Системы пакетной обработки — Справочник химика 21
Одно из таких понятий — пакетная обработка . В ЭВМ общепринятым способом вводятся один за другим пакеты , каждый из которых представляет собой данные, подлежащие обработке, и соответствующую программу. Ввод обычно осуществляется при помощи перфокарт или перфолент, но пакетами можно управлять и на расстоянии — с помощью телетайпа. Отдельные пакеты обрабатываются последовательно, по соответствующему расписанию или по мере освобождения ЭВМ. При этом время ЭВМ используется рационально, но между моментами получения масс-спектрометрических данных и выдачи результатов появляется некоторая задержка, которая может составлять от нескольких минут до суток. Система пакетной обработки может включать от одной программы до десятков или сотен и применяется как на малых, так и на самых больших ЭВМ. Системы [c.217]
В ЭВМ общепринятым способом вводятся один за другим пакеты , каждый из которых представляет собой данные, подлежащие обработке, и соответствующую программу. Ввод обычно осуществляется при помощи перфокарт или перфолент, но пакетами можно управлять и на расстоянии — с помощью телетайпа. Отдельные пакеты обрабатываются последовательно, по соответствующему расписанию или по мере освобождения ЭВМ. При этом время ЭВМ используется рационально, но между моментами получения масс-спектрометрических данных и выдачи результатов появляется некоторая задержка, которая может составлять от нескольких минут до суток. Система пакетной обработки может включать от одной программы до десятков или сотен и применяется как на малых, так и на самых больших ЭВМ. Системы [c.217] СИСТЕМЫ ПАКЕТНОЙ ОБРАБОТКИ [c.227]
Распределение функций между системами реального времени (телемеханический комплекс и мини-ЭВМ) и системой пакетной обработки (универсальная ЭВМ) осуществляется следующим образом. [c.77]
[c.77]
Основу системного математического обеспечения составляет операционная система (ОС ЕС или ОС СМ). Для различных моделей ЭВМ разработано несколько разновидностей ОС. В наибольшей степени для решения задач САПР приспособлены ОС с разделением времени. Состав операционной системы ЕС ЭВМ представлен на рис. 6.5. В зависимости от режима работы можно выделить три уровня ОС для пакетной обработки заданий, для пакетной обработки с мультипрограммированием, для работы в режиме разделения времени. [c.248]
При пакетной обработке на входе вычислительной системы имеется пакет (набор) заданий, последовательно выполняемых ЭВМ. Каждое задание может использовать все ресурсы системы за исключением некоторого объема оперативной памяти, постоянно занимаемой резидентной частью ОС. Пакетный режим работы позволяет исключить простои процессора за счет отстранения пользователя от ЭВМ (задания выполняются автоматически по управляющим операторам ОС) и частичного совмещения операций ввода-вывода и работы процессора. Однако [c.248]
Однако [c.248]
В связи с этим следует особо остановиться на программе (системе программ), организующей вычислительный процесс. В настоящее время теория разработки и формализованные методы описания таких программ практически отсутствуют, а на индивидуальные их разработки требуются значительные средства и время. Поэтому в подсистеме расчета МТБ ХТС, как и в других подсистемах АСП, желательно использовать стандартные организующие программы, поставляемые изготовителем ЭВМ в составе математического обеспечения. Выбор типа системы обслуживания (например, мониторная, мультипрограммная, разделение времени, онлайновая, пакетная обработка) зависит в основном от технического оснащения, объема решаемых задач и их количества, числа пользователей. [c.81]
В гл. 7 подробно описано использование ЭВМ для количественного определения следов элементов методами, изложенными в гл. 6. Рассматриваются и сопоставляются в применении к масс-спектрометрии устройства пакетной обработки, системы с разделением времени и машины, предназначенные специально для данных приборов. [c.11]
[c.11]
Системы с разделением времени открывают новый путь использования ЭВМ, основанный на возможности вмешательства человека в выполнение логических операций. Это направление разработано и используется пока еще недостаточно полно. Взаимодействие с ЭВМ исключительно перспективно и полезно, однако оно не может осуществляться само по себе каждый контакт между человеком и ЭВМ должен быть тщательно спланирован и включен в программу. Часто можно встретить программы, предварительно записанные для режима пакетной обработки, а затем просто преобразованные для систем с разделением времени с небольшими изменениями либо без них. Подобные программы обычно совсем не позволяют человеку участвовать в процессе расчета, чтобы отбрасывать возможные ошибочно введенные данные. Иногда такие программы могут быть более удобны в обращении и заметно сократят время получения результатов анализа. [c.232]
В системах с разделением времени в большинстве случаев используются те же языки, что и при пакетной обработке, или очень близкие к ним ( диалекты ). Иногда для этих целей создаются специальные языки. Существуют несколько действительно многоязычных систем. Например, система с разделением времени, использующаяся фирмой R A (Принстон, Нью-Джерси, США) и называющаяся ФОРТРАН ПИ, включает в качестве основного языка ФОРТРАН IV, помимо этого, многие положения взяты из языков АЛГОЛ, БЕЙСИК, ПЛ/1 и др. В программу можно также включать отдельные положения на языке ассемблера или машинном языке в шестнадцатеричном исчислении. Для мини-ЭВМ программа обычно составляется на языке ассемблера, поскольку эти машины имеют ограниченный объем основной памяти и редко используются как ЭВМ общего назначения. [c.243]
Иногда для этих целей создаются специальные языки. Существуют несколько действительно многоязычных систем. Например, система с разделением времени, использующаяся фирмой R A (Принстон, Нью-Джерси, США) и называющаяся ФОРТРАН ПИ, включает в качестве основного языка ФОРТРАН IV, помимо этого, многие положения взяты из языков АЛГОЛ, БЕЙСИК, ПЛ/1 и др. В программу можно также включать отдельные положения на языке ассемблера или машинном языке в шестнадцатеричном исчислении. Для мини-ЭВМ программа обычно составляется на языке ассемблера, поскольку эти машины имеют ограниченный объем основной памяти и редко используются как ЭВМ общего назначения. [c.243]
На основе моделирования разрабатываются способы присвоения приоритетов как путем выделения обслуживаемых с преимуществом потребителей, таки по признакам, присваиваемым отдельным запросам на основе анализа их индивидуальных свойств. Установление рациональной схемы приоритетов позволяет в определенных границах достигнуть необходимого компромисса между требованиями потребителей на сокращение времени решения задач и требованием увеличения суммарной производительности системы. Моделирование позволяет также определить рациональные режимы сочетания обслуживания индивидуальных запросов в соответствии с их приоритетом с режимами накопления и пакетной обработки. Такие способы организации работы позволяют осуществить сглаживание пиковых нагрузок и перераспределение обслуживания части заявок на более длительные отрезки времени. В процессе моделирования могут быть уточнены характеристики обслуживающей системы способы загрузки автономных устройств и вычислительной системы в целом, организация совмещения операций, способы рационального размещения информации в информационном накопителе и распределения полей ОЗУ в различных ситуациях и др. [c.61]
Моделирование позволяет также определить рациональные режимы сочетания обслуживания индивидуальных запросов в соответствии с их приоритетом с режимами накопления и пакетной обработки. Такие способы организации работы позволяют осуществить сглаживание пиковых нагрузок и перераспределение обслуживания части заявок на более длительные отрезки времени. В процессе моделирования могут быть уточнены характеристики обслуживающей системы способы загрузки автономных устройств и вычислительной системы в целом, организация совмещения операций, способы рационального размещения информации в информационном накопителе и распределения полей ОЗУ в различных ситуациях и др. [c.61]
Наконец, самое важное качество — это возможность быстрого получения результатов трансляции и проверочного прогона программы, отсутствующее при работе в вычислительных центрах с пакетной обработкой данных. Система с разделением времени позволяет исследователю, не отходя от терминала, вносить изменения в программу сразу после проверочного прогона и прогонять новый вариант.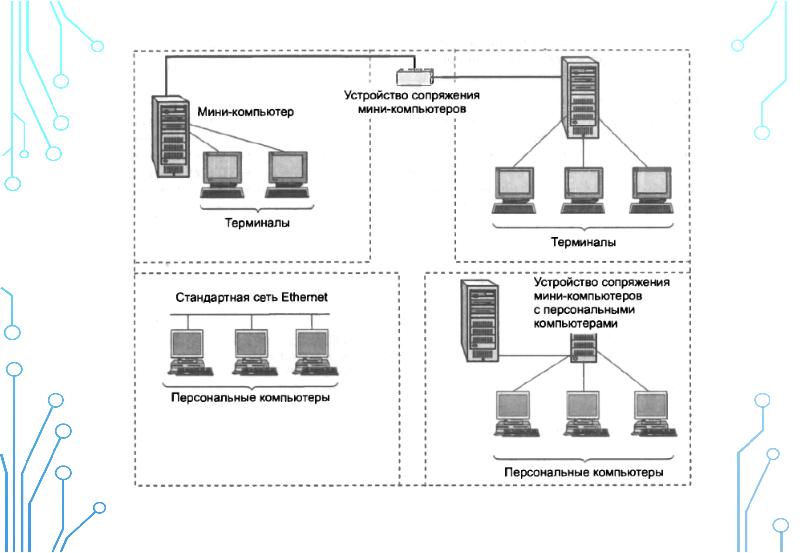 [c.68]
[c.68]
Фоновый режим. Использование времени ЭВМ, свободного от решения задач в масштабе реального времени, для пакетной обработки информации с помощью операционной системы. [c.295]
Как правило, в таких системах обработка и переработка собранной при помощи телемеханических комплексов и систем передачи данных информации осуществляются на комплексах реального времени (УВМ типа СМ) и пакетной обработки (ЭВМ типа ЕС). [c.79]
Основными структурами технических средств САПР являются конфигурации на базе больших ЭВМ единой серии (ЕС ЭВМ) и на базе мини-ЭВМ (СМ ЭВМ). Системы проектирования на базе ЕС ЭВМ используются в основном в крупных научно-исследовательских и проектных институтах как в пакетном режиме, так и с развитой системой разделения времени. На базе мини-ЭВМ строятся автоматизированные рабочие места (АРМ), предназначенные для решения частных задач проектирования, обработки графической информации. Бурное развитие микроЭВМ способствует появлению персональных терминалов, которые, возможно, в будущем заменят АРМ на базе мини-ЭВМ. [c.232]
[c.232]
В свою очередь ограничения, накладываемые относительно небольшим объемом оперативной памяти, приводят к тому, что операционные системы мини-ЭВМ относительно просты и не требуют больших объемов памяти. Эти операционные системы, как правило, являются специализированными и эффективно реализуют только один из режимов работы пакетный, разделения времени и т. д. Использование в мини-ЭВМ универсальных операционных систем типа ОС ЕС неприемлемо, поскольку стоимость разработки такой операционной системы будет велика но сравнению со стоимостью мини-ЭВМ, кроме ТОГО, такая операционная система займет практически всю оперативную память, что не позволит эффективно производить обработку информации. [c.134]
Повышения эффективности использования вычислительной системы можно достигнуть, во-первых, за счет сокращения времени простоя процессора и, во-вторых, за счет сокращения времени ожидания решения в режиме пакетной обработки. Классическим примером повышения производительности ЭВМ является многопрограммный режим, или мультипрограммирование. Идея этого метода состоит в том, что ЭВМ настраивается на одновременное выполнение ряда задач, каждая из которых занимает часть оперативной памяти. Поскольку большинство внешних устройств может работать в автономном режиме после загрузки соответствующего канала, то совмещением работы внешних устройств и процессора можно достигнуть максимальной загрузки последнего. Как только одна из программ приостанавливается для выполнения, например, операции ввод-вывода, процессор переключается на выполнение другой программы, тем самым исключается время его ожидания. Разделам памяти присваиваются уров ни приоритетности, которые и определяют последовательность переключения программ. Этот режим не предполагает непосредственного доступа пользователя к ЭВМ, так как в каждом разделе памяти производится пакетная обработка программ. Однако за счет лучшего использования оборудования время ожидания решения обычно сокращается по сравнению с однопрограммным режимом. Разновидностью режима мультипрограммирования является параллельная обработка, идея которой состоит в том, что переход от одной программы к другой производится в результате естественного прерывания (ожидания ввода-вывода) и вынужденного переключения через короткие промежутки времени, сравнимые со скоростью работы процессора.
Идея этого метода состоит в том, что ЭВМ настраивается на одновременное выполнение ряда задач, каждая из которых занимает часть оперативной памяти. Поскольку большинство внешних устройств может работать в автономном режиме после загрузки соответствующего канала, то совмещением работы внешних устройств и процессора можно достигнуть максимальной загрузки последнего. Как только одна из программ приостанавливается для выполнения, например, операции ввод-вывода, процессор переключается на выполнение другой программы, тем самым исключается время его ожидания. Разделам памяти присваиваются уров ни приоритетности, которые и определяют последовательность переключения программ. Этот режим не предполагает непосредственного доступа пользователя к ЭВМ, так как в каждом разделе памяти производится пакетная обработка программ. Однако за счет лучшего использования оборудования время ожидания решения обычно сокращается по сравнению с однопрограммным режимом. Разновидностью режима мультипрограммирования является параллельная обработка, идея которой состоит в том, что переход от одной программы к другой производится в результате естественного прерывания (ожидания ввода-вывода) и вынужденного переключения через короткие промежутки времени, сравнимые со скоростью работы процессора. При параллельной обработке программы выполняются по очереди в короткие промежутки времени и создается впечетление их одновременного выполнения, тем более что результаты расчета выдаются пользователю по мере завершения каждой из них. [c.249]
При параллельной обработке программы выполняются по очереди в короткие промежутки времени и создается впечетление их одновременного выполнения, тем более что результаты расчета выдаются пользователю по мере завершения каждой из них. [c.249]
Значительное сокращение времени простоя процессора было достигнуто с введением режима пакетной обработки, заключающегося в том, что составляются наборы (пакеты) программ и периодически загружаются по заданию оператора во внешнюю память. В дальнейшем они выполняются под управлением специальных программ (в частности, под управлением операционной системы). Увеличение производительности системы в этом случае достигается за счет совмещения работы чнешних устройств и процессора ЭВМ, однако решение отдельных задач (особенно с отладкой) существенно замедляется, так как программист пе имеет непосредственного доступа к ЭВМ и может вносить изменения в программу, а также получать результаты расчета только по окончании обработки пакета. Таким образом, здесь наблюдается обратная ситуация время реакции пользователя меньше времени реакции ЭВМ, к тому же пользователь лишен возможности диалога. [c.191]
Таким образом, здесь наблюдается обратная ситуация время реакции пользователя меньше времени реакции ЭВМ, к тому же пользователь лишен возможности диалога. [c.191]
Программы, записанные для систем пакетной обработки, исторически предшествуют программам для устройства с разделением времени, и являются основным методом машинной обработки результатов в масс-спектрометрии с искровым источником ионов. В литературе более или менее подробно рассмотрен ряд систем и программ для систем пакетной обработки. В большинстве из них исходные данные считываются с фотопластины вручную при помощи микрофотометра и печатаются на перфокартах или бумажной ленте. Одной из первых попыток обработки масс-спектрометрических данных с помощью простой программы пакетной обработки, записанной на языке ФОРТРАН, посвящена работа Кепникота (1964). Программа была основана на способе калибровки фотопластин, разработанном Черчиллем (1944). В более поздней работе (Кенникот, 1966) предложена новая система накопления данных. Система записывает на магнитной ленте в аналоговой форме профиль каждой спектральной линии, выбранной аналитиком для расчета. После проведения сканирования всех необходимых линий эта магнитная лента направляется в ЭВМ и объединяется с отпечатанными на картах дополнительными данными, необходимыми для идентификации линий и для расчета, — образуется пакет данных, ЭВМ снабжена приспособлением для перевода аналоговой записи на ленте в цифровую форму. Вулстон (1965) описал систему, в которую данные вводятся пробитыми на перфокартах. Для калибровки фотопластин было использовано уравнение Халла (1962). В формулу Халла входят два коэффициента, которые необходимо определять отдельно как для основы, так и для каждой примеси. Но программа составлена таким образом, что эти величины рассчитываются автоматически достаточно ввести в ЭВМ исходные данные для трех элементов. В программу входят все используемые обычно поправочные коэффициенты (зависимость чувствительности фотопластины от массы иона, учет фона, распределения ионов по зарядностям, коэффициенты относительной чувствительности) производится расчет пределов обнаружения, ошибок эксперимента и выдача полных результатов анализа.
Система записывает на магнитной ленте в аналоговой форме профиль каждой спектральной линии, выбранной аналитиком для расчета. После проведения сканирования всех необходимых линий эта магнитная лента направляется в ЭВМ и объединяется с отпечатанными на картах дополнительными данными, необходимыми для идентификации линий и для расчета, — образуется пакет данных, ЭВМ снабжена приспособлением для перевода аналоговой записи на ленте в цифровую форму. Вулстон (1965) описал систему, в которую данные вводятся пробитыми на перфокартах. Для калибровки фотопластин было использовано уравнение Халла (1962). В формулу Халла входят два коэффициента, которые необходимо определять отдельно как для основы, так и для каждой примеси. Но программа составлена таким образом, что эти величины рассчитываются автоматически достаточно ввести в ЭВМ исходные данные для трех элементов. В программу входят все используемые обычно поправочные коэффициенты (зависимость чувствительности фотопластины от массы иона, учет фона, распределения ионов по зарядностям, коэффициенты относительной чувствительности) производится расчет пределов обнаружения, ошибок эксперимента и выдача полных результатов анализа. Эта программа была записана на языке ассемблера, соответствующем группе ЭВМ КСА-601. Очень гибкая программа на языке АЛГОЛ предложена Франценом и Шуи [c.227]
Эта программа была записана на языке ассемблера, соответствующем группе ЭВМ КСА-601. Очень гибкая программа на языке АЛГОЛ предложена Франценом и Шуи [c.227]
В описанное устройство входит ЭВМ среднего размера PDP-10, работающая в режиме разделения времени по особой программе. Аналогичные ЭВМ использованы в исследовательских лабораториях фирмы IBM (Сан-Хосе, Калифорния, США). Эти системы осуществляют автоматический контроль и обработку данных для ряда связанных с ними приборов и могут также проводить пакетную обработку данных. Связь осуществлена по принципу так называемых переднего и заднего планов, т. е. первый класс перечисленных задач всегда имеет преимущество перед вторым. Несколько отличная автоматическая система примерно того же объема имеется в лабораториях по исследованию излучений (Ливермор, Калифорния, США). Эта система, в состав которой входит ЭВМ PDP-7, описана в прекрасном обзоре Фразера (1970). В работе Кука и сотр. (1965) описана система меньшего масштаба, в которой с ЭВМ SDS-910 соединены масс-спектрометр с термоионным источником и микрофотометр, но обработка данных производится не в момент их получения, а после предварительного накопления с последующим вводом в ЭВМ. [c.237]
[c.237]
Пакетная обработка. Пакет работ подается на машину и рз боты выполняются одна за другой в порядке, избранном операционной системой, обычно в режиме мультпрограммирования. В машинах предыдущего поколения пользователь наблюдал за процессом выполнения своей программы, следил, верно ли она идет, вводил новые параметры, меняющие ее ход, оперативно вносил в нее исправления. [c.53]
Большой объем памяти центральной ЭВМ и наличие дискориентированной операционной системы дает возможность использовать Фортран и макроассемблер. Операционная система также позволяет вести пакетную обработку задач в фоновом режиме или режиме решения основных задач в заранее известном интервале времени, когда от контролируемого ЭВМ экспериментального процесса не поступают запросы на прерывания. [c.55]
Вычислительная система с разделением времени между большим числом терминалов, работающая в режиме двустороннего взаимодействия с исследователями, лучше всего отвечает требованиям научно-исследовательских институтов, особенно их аналитических лабораторий. Кроме этого, исследователям, использующим систему для расчетов в автономном режиме, предоставляется прекрасная возможность быстрой проверки и отладки программ с какого-нибудь оконечного телетайпа без всякой затраты времени и усилий на пакетную обработку данных в вычислительном центре. Это особенно удобно при выполнении небольших задач, которые можно запрограммировать и немедленно пропустить с какого-либо терминала, используя языки высокого уровня, такие как Бэзик и Фортран. [c.84]
Кроме этого, исследователям, использующим систему для расчетов в автономном режиме, предоставляется прекрасная возможность быстрой проверки и отладки программ с какого-нибудь оконечного телетайпа без всякой затраты времени и усилий на пакетную обработку данных в вычислительном центре. Это особенно удобно при выполнении небольших задач, которые можно запрограммировать и немедленно пропустить с какого-либо терминала, используя языки высокого уровня, такие как Бэзик и Фортран. [c.84]
Существующие СУБД можно подразделить на специализированные и универсальные. Специализированные ориентиро- ваны только на конкретное применение, например применение СУБД СИОД возможно только на предприятиях с дискретным характером производства. В самых различных областях после соответствующей настройки могут быть использованы универсальные СУБД, например система Банк для проектирования банков данных сетевой структуры, системы Ока и Кама для создания иерархических банков. Эти системы позволяют реализовать два режима функционирования АСУ пакетную обработку данных и телеобработку данных в режи ме реального времени. [c.96]
[c.96]
Рассматриваемая автоматизированная система управления в отличие от представленных систем разработана на базе телемеханических комплексов УВТК-120-1 в составе АСУ ТП КСАСУ ТП УМГ-АСУ ТП ПО. Система в общем случае может работать как информа-ционно-управляющая в двух режимах 1) с ограниченными возможностями (когда управление системой осуществляется с ПУ УВТК-120-1 диспетчером) и 2) с расширенными возможностями (управление осуществляется при помощи комплекса УВМ — в реальном масштабе времени и ЭВМ — в режиме пакетной обработки с участием диспетчера системы). [c.75]
2.4.1 Планирование в системах пакетной обработки данных . Операционные системы
1 «Первым пришёл – первым ушёл»
Самый простой алгоритм планирования. Категория алгоритма – без переключений. Процессам предоставляется доступ к процессору в том порядке, в котором они его запрашивают. Формируется единая очередь процессов. Когда текущий процесс блокируется, запускается следующий в очереди, а когда блокировка снимается, процесс попадает в конец очереди. Недостаток в том, что если существует очередь процессов, в котором есть процессы ограниченные устройствами ввода-вывода (т.е. большую часть времени тратящие на ожидание устройств), то это ожидание будет означать простой процессора.
Недостаток в том, что если существует очередь процессов, в котором есть процессы ограниченные устройствами ввода-вывода (т.е. большую часть времени тратящие на ожидание устройств), то это ожидание будет означать простой процессора.
2 Алгоритм «Кратчайшая задача – первая»
Категория алгоритма – без переключений. Суть алгоритма заключается в следующем: если в очереди есть несколько одинаково важных задач, планировщик выбирает первой самую короткую по времени. Эта схема работает лишь в случае одновременного наличия задач и обычно неактуальна.
3 Алгоритм «Наименьшее оставшееся время выполнения»
Версия предыдущего алгоритма. В соответствии с этим алгоритмом, планировщик каждый раз выбирает процесс с наименьшим оставшимся временем выполнения. Естественно для таких алгоритмов необходимо знать, сколько времени выполняются процессы, что обычно является сложной задачей.
4 Алгоритм трехуровневого планирования
Системы пакетной обработки позволяют реализовать трехуровневое планирование, как показано на рисунке 15. По мере поступления в систему новые задачи сначала помещаются в очередь, хранящуюся на диске. Планировщик доступа выбирает задание и передает его системе. Остальные задачи остаются в очереди. Выбор заданий обуславливается установленным приоритетом – по времени выполнения или как-то по другому, например по работе с устройствами вводавывода.
По мере поступления в систему новые задачи сначала помещаются в очередь, хранящуюся на диске. Планировщик доступа выбирает задание и передает его системе. Остальные задачи остаются в очереди. Выбор заданий обуславливается установленным приоритетом – по времени выполнения или как-то по другому, например по работе с устройствами вводавывода.
Рисунок 15 – Трехуровневое планирование
Как только задание попало в систему, для него будет создан соответствующий процесс, который вступает в борьбу за доступ к процессору. В ситуации, когда процессов слишком много, работает второй уровень планирования (планировщик памяти), который определяет, какие процессы будут находиться в памяти, а какие можно выгрузить на диск. Естественно это не должно происходить слишком часто, т.к. дисковые операции сравнительно медленные. Количество процессов, одновременно находящихся в памяти, называется степенью многозадачности.
Данный текст является ознакомительным фрагментом.
Лабораторная работа 2. Файлы пакетной обработки данных. Операторы пакетных файлов.
Цель работы :
приобретение практических навыков создания и применения файлов пакетной обработки. Работа рассчитана на 4 часа.
Краткие теоретические сведения.
Понятие пакетного файла.
Пакетным или командным называется текстовый файл, в каждой строке которого записана команда DOS или имя какого либо программного файла. Пакетные файлы предназначены для упрощения задания и ввода некоторой, часто используемой последовательности команд. Чтобы DOS смогла распознать эти файлы им присваивается специальное расширение .bat.
Это
расширение распознаёт файл command. com.
Пакетный файл может содержать любые
команды, вводимые в командной строке в
том числе и с перенаправлением ввода-вывода
и конвейеры. Кроме того в пакетных файлах
используются команды, которые предназначены
, главным образом для пакетных файлов,
хотя могут быть использованы и в командной
строке. При использовании специальных
возможностей можно создавать сложные
пакетные файлы, которые похожи на
программы. Пакетные файлы создаются
также как и обычные текстовые файлы, то
есть или при помощи текстового редактора
или при помощи команды COPY CON. В качестве
строки в пакетном файле может быть
включено имя другого пакетного файла
то есть можно создавать цепочки пакетных
файлов. Однако следует помнить, что при
передаче управления другому пакетному
файлу, без специальных условий, не
происходит возврат в прежний пакетный
файл.
com.
Пакетный файл может содержать любые
команды, вводимые в командной строке в
том числе и с перенаправлением ввода-вывода
и конвейеры. Кроме того в пакетных файлах
используются команды, которые предназначены
, главным образом для пакетных файлов,
хотя могут быть использованы и в командной
строке. При использовании специальных
возможностей можно создавать сложные
пакетные файлы, которые похожи на
программы. Пакетные файлы создаются
также как и обычные текстовые файлы, то
есть или при помощи текстового редактора
или при помощи команды COPY CON. В качестве
строки в пакетном файле может быть
включено имя другого пакетного файла
то есть можно создавать цепочки пакетных
файлов. Однако следует помнить, что при
передаче управления другому пакетному
файлу, без специальных условий, не
происходит возврат в прежний пакетный
файл.
При необходимости прервать выполнение пакетного файла необходимо нажать комбинацию клавиш Ctrl — Break, в результате чего на экране появится сообщение
Terminate bath job (Y/N)?
Пример
пакетного файла с именем PRIM. BAT
BAT
DIR A:\ /W
DIR C:\ /W
Пример: написать пакетный файл, который выполняет следующие функции:
получает оглавление текущего каталога текущего диска, сортирует оглавление каталога в обратном алфавитном порядке и выводит его на экран постранично. Имя файла CAT.BAT
DIR|SORT /R|MORE
Пример: написать пакетный файл, который защищает все программные файлы в текущем каталоге от изменения. В пакетный файл необходимо включить проверку, что эта операция произведена.
ATTRIB +R *.EXE
ATTRIB +R *.COM
ATTRIB *.*
4.8.2 Индикация сообщений в пакетном файле.
1. Команда cls.
Команда CLS предназначена для очистки экрана. Обычно команда CLS является одной из первых в пакетном файле. Эта команда не имеет параметров и ключей. При её выполнении вся информация с экрана исчезает, а курсор переходит в левый верхний угол.
2. Команда echo.
При
выполнении пакетного файла, если не
приняты некоторые условия, на экране
появляются сами команды перед их
выполнением. Обычно удобнее наблюдать
не сами команды, а результат их выполнения.
Для того чтобы избежать появления на
экране команд используется команда
ECHO.
Обычно удобнее наблюдать
не сами команды, а результат их выполнения.
Для того чтобы избежать появления на
экране команд используется команда
ECHO.
Общий формат команды ECHO
ECHO [ OFF|ONN сообщение ]
Если ввести команду ECHO без параметров, то на экране появится её текущее состояние то есть ECHO в состоянии ON или ECHO в состоянии OFF.
Если команда ECHO задана с параметром OFF, то на экран не будут выводится имена команд, которые находятся в пакетном файле ниже этой команды. Команда ECHO “сообщение” будет выводить на экран само “сообщение” без слова ECHO.
Символ @ , помещённый в начале командной строки, запрещает вывод имени команды, записанной в этой строке.
Пакетная обработка и оркестровка рабочей нагрузки: обзор
Что такое пакетная обработка рабочих нагрузок? Пакетная обработка рабочей нагрузки относится к группам заданий (пакетам), которые должны обрабатываться одновременно. Традиционно пакетные рабочие нагрузки обрабатываются во время пакетных окон, периодов времени, когда общая загрузка ЦП низкая (обычно в ночное время). Причина этого двоякая:
Традиционно пакетные рабочие нагрузки обрабатываются во время пакетных окон, периодов времени, когда общая загрузка ЦП низкая (обычно в ночное время). Причина этого двоякая:
- Пакетные рабочие нагрузки могут потребовать высоких процессоров, занимая ресурсы, необходимые для других операционных процессов в течение рабочего дня
- Пакетные рабочие нагрузки обычно используются для обработки транзакций и создания отчетов, например, для сбора всех записей о продажах, которые были созданы в течение рабочего дня. рабочего дня
Сегодня пакетная обработка выполняется с помощью планировщиков заданий, систем пакетной обработки, решений для автоматизации рабочих нагрузок и приложений, встроенных в операционные системы.Инструмент пакетной обработки получает входные данные, учитывает системные требования и координирует планирование для обработки больших объемов. Пакетная обработка отличается от потоковой обработки тем, что для пакетной обработки требуется прерывистая информация.
Пакетная обработка уходит корнями в предысторию компьютеров. Еще в 1890 году Бюро переписи населения США использовало электромеханический табулятор для записи информации переписи населения США.Герман Холлерит, который изобрел табулятор, основал компанию, которая, в свою очередь, стала IBM.
Суперкомпьютер CDC 6600, около 1964 г. / Фото Арнольда РейнхольдаК середине 20 века пакетные задания выполнялись с использованием данных, перфорированных на картах. В 1960-х годах с развитием мультипрограммирования компьютерные системы начали выполнять несколько пакетных заданий одновременно для обработки данных с магнитной ленты вместо перфокарт.
По мере развития и становления мэйнфреймов более мощными, выполнялось все больше пакетных заданий, и поэтому были разработаны приложения, обеспечивающие выполнение пакетных заданий только при наличии достаточных ресурсов, чтобы предотвратить задержки.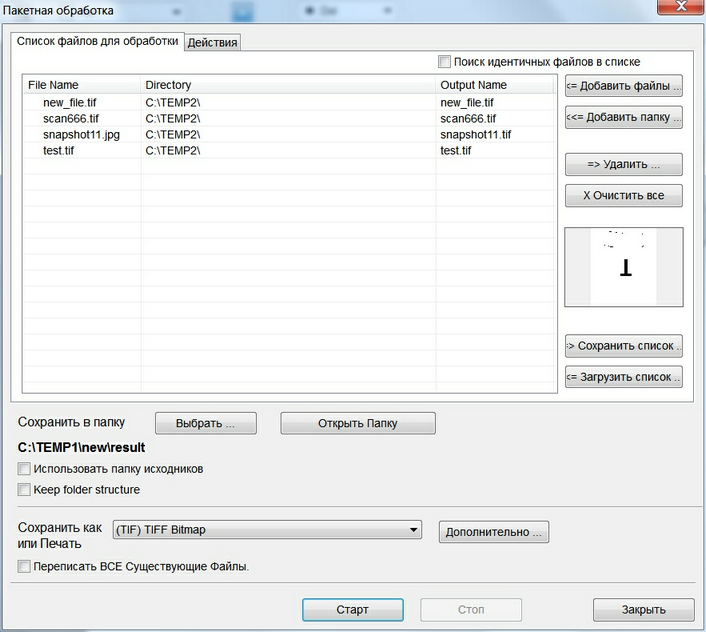 Это помогло создать современные системы пакетной обработки.
Это помогло создать современные системы пакетной обработки.
Варианты использования пакетной обработки можно найти в банках, больницах, бухгалтерии и любой другой среде, где необходимо обрабатывать большой набор данных. Например, генерация отчетов запускается после закрытия бизнеса, когда все транзакции по кредитным картам были завершены. Коммунальные предприятия собирают данные об использовании клиентами и запускают пакетные процессы для определения выставления счетов.
В другом случае компания по управлению финансовыми данными запускает пакетные процессы в ночное время, которые предоставляют финансовые отчеты непосредственно банкам и финансовым учреждениям, которые они обслуживают.
Преимущества и недостатки Пакетная обработка Пакетная обработка полезна, поскольку она обеспечивает метод обработки больших объемов данных без использования ключевых вычислительных ресурсов. Если поставщику медицинских услуг необходимо обновить записи о выставлении счетов, возможно, лучше всего запустить пакет в течение ночи, когда потребности в ресурсах будут низкими.
Если поставщику медицинских услуг необходимо обновить записи о выставлении счетов, возможно, лучше всего запустить пакет в течение ночи, когда потребности в ресурсах будут низкими.
Точно так же пакетная обработка помогает сократить время простоя за счет выполнения заданий, когда доступны вычислительные ресурсы.
Однако средства пакетной обработкичасто ограничены по объему и возможностям. Пользовательские сценарии часто требуются для интеграции пакетной системы с новыми источниками данных, что может создавать проблемы кибербезопасности при включении конфиденциальных данных. Традиционные пакетные системы также могут быть плохо приспособлены для обработки процессов, требующих данных в реальном времени, например потоковой обработки или обработки транзакций.
Ваш центр обработки данных идет в ногу с бизнесом?
Узнайте, как преодолеть сложность центра обработки данных с помощью решения по планированию корпоративных заданий.
Современные Системы пакетной обработки
Современные системы пакетной обработки предоставляют ряд возможностей, которые упрощают группам управление большими объемами рабочих нагрузок. Это может включать автоматизацию на основе событий , ограничения и мониторинг в реальном времени.Эти современные возможности помогают гарантировать выполнение пакетов только при наличии всех необходимых данных, сокращая задержки и ошибки.
Это может включать автоматизацию на основе событий , ограничения и мониторинг в реальном времени.Эти современные возможности помогают гарантировать выполнение пакетов только при наличии всех необходимых данных, сокращая задержки и ошибки.
Чтобы еще больше сократить задержки, современные системы пакетной обработки включают алгоритмы балансировки нагрузки, чтобы гарантировать, что пакетные задания не отправляются на серверы с нехваткой памяти или недостаточным количеством доступных ЦП.
Между тем, расширенные возможности планирования даты / времени позволяют планировать пакеты с учетом настраиваемых праздников, финансовых календарей, нескольких часовых поясов и многого другого.
Однако из-за растущей потребности в данных в реальном времени и возрастающей сложности современной обработки данных многие ИТ-организации выбирают платформы автоматизации и оркестрации рабочих нагрузок , которые предоставляют расширенные инструменты для управления данными и интеграции.
Современный ИТ-отдел разнообразен, распределен и динамичен. Вместо того чтобы полагаться на однородные мэйнфреймы и локальные центры обработки данных, пакетные процессы выполняются в гибридных средах .Для этого есть веская причина.
Как упоминалось ранее, пакетные процессы часто требуют значительных ресурсов. Сегодня, с ростом больших объемов данных и онлайн-транзакций, пакетные рабочие нагрузки могут потребовать довольно много. Использование облачной инфраструктуры дает ИТ-отделам возможность выделять вычислительные ресурсы по запросу, вместо того, чтобы устанавливать физические серверы, которые в течение значительного времени дня, вероятно, будут простаивать.
Объем данных, которыми ИТ-отдел должен управлять для удовлетворения потребностей бизнеса, продолжает расти, и инструменты пакетной обработки рабочих нагрузок развиваются для удовлетворения этих потребностей.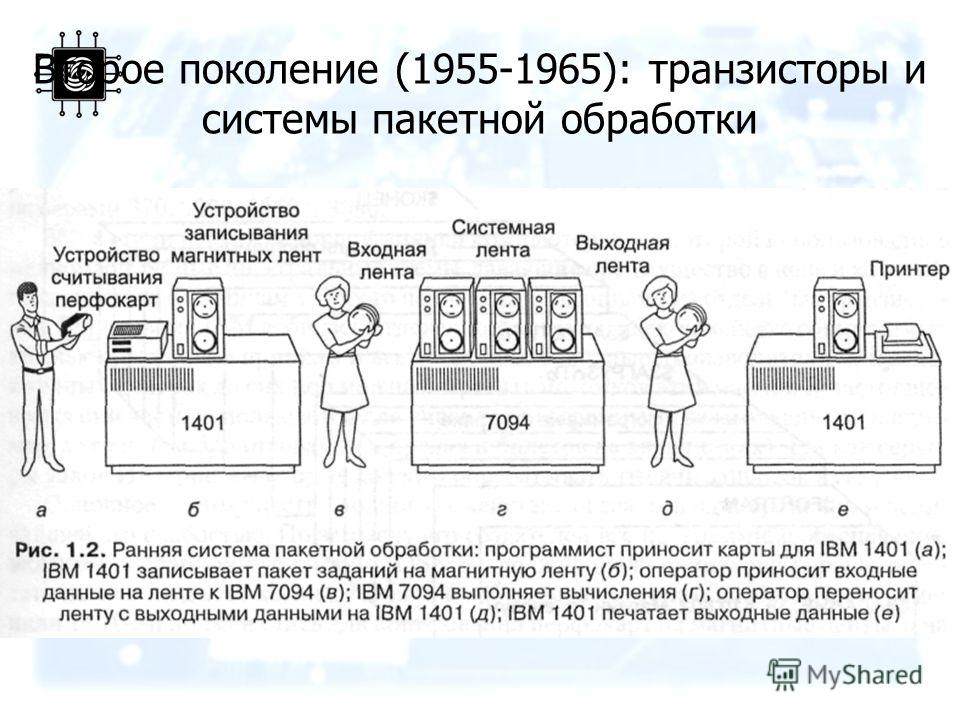 Например, у ИТ-отдела нет ресурсов, необходимых для ручного выполнения каждого процесса ETL или для ручной настройки, подготовки и деинициализации виртуальных машин. Вместо этого используются инструменты пакетной обработки для автоматизации и согласования этих задач в сквозные процессы.
Например, у ИТ-отдела нет ресурсов, необходимых для ручного выполнения каждого процесса ETL или для ручной настройки, подготовки и деинициализации виртуальных машин. Вместо этого используются инструменты пакетной обработки для автоматизации и согласования этих задач в сквозные процессы.
Например, инструмент автоматизации и оркестровки может использоваться для перемещения данных в различные компоненты кластера Hadoop и из них как часть сквозного процесса, который включает в себя подготовку виртуальных машин, выполнение заданий ETL на платформе BI, а затем доставка этих отчетов по электронной почте.
По мере того, как организации становятся все более зависимыми от облачных ресурсов и приложений, способность координировать планирование заданий и пакетные рабочие нагрузки на разрозненных платформах становится критически важной.
Пакетная оркестровка рабочей нагрузки Инструменты автоматизации и оркестрации становятся все более расширяемыми, при этом несколько решений для автоматизации рабочих нагрузок уже предоставляют универсальные соединители и адаптеры REST API с низким кодом, которые позволяют интегрировать практически любой инструмент или технологию без написания сценариев.
Это важно, потому что вместо того, чтобы планировщики заданий, инструменты автоматизации и пакетные процессы выполнялись изолированно, ИТ-отдел может использовать инструмент оркестровки рабочих нагрузок для централизованного управления, мониторинга и устранения неполадок всех пакетных заданий.
Инструменты оркестровки ИТ могут, например, автоматически создавать и сохранять файлы журналов для каждого экземпляра пакета, что позволяет ИТ-специалистам быстро определять основные причины возникновения проблем. Мониторинг и оповещение в режиме реального времени позволяют ИТ-специалистам реагировать или предотвращать задержки, сбои и незавершенные запуски, ускоряя время реакции при возникновении проблем.
Автоматические перезапуски и рабочие процессы автоматического исправления также становятся все более распространенными, в то время как пакетным заданиям можно назначать приоритеты, чтобы гарантировать доступность ресурсов во время выполнения.
Кроме того, расширяемые инструменты пакетной обработки позволяют консолидировать унаследованные сценарии и пакетные приложения, что позволяет ИТ-специалистам упростить и сократить эксплуатационные расходы.
Традиционное пакетное планирование Инструменты уступили место высокопроизводительным платформам автоматизации и оркестрации, которые обеспечивают расширяемость, необходимую для управления изменениями.Они позволяют ИТ-специалистам работать в гибридных и мультиоблачных средах и могут значительно снизить потребность в человеческом вмешательстве.
алгоритмы машинного обучения используются для интеллектуального распределения виртуальных машин для пакетных рабочих нагрузок, чтобы сократить время простоя и простоя ресурсов. Это критически важно для команд, управляющих запусками больших объемов рабочих нагрузок или с большим количеством виртуальных или облачных серверов.
Благодаря машинному обучению, работающему в режиме реального времени, можно зарезервировать дополнительные ресурсы, если критически важная для SLA рабочая нагрузка подвержена риску выхода за пределы. Это включает в себя подготовку дополнительных виртуальных или облачных машин на основе динамического спроса. В сочетании с автоматическим исправлением это дает мощный инструмент, позволяющий убедиться, что предоставление услуг не задерживается для конечного пользователя или внешнего клиента.
Это включает в себя подготовку дополнительных виртуальных или облачных машин на основе динамического спроса. В сочетании с автоматическим исправлением это дает мощный инструмент, позволяющий убедиться, что предоставление услуг не задерживается для конечного пользователя или внешнего клиента.
В долгосрочной перспективе ИТ становятся все более разнообразными и распределенными, а типы рабочих нагрузок, за которые отвечает ИТ, будут продолжать расширяться. Развитие новых технологий — искусственного интеллекта, Интернета вещей и периферийных вычислений — заставит ИТ-команды быстро интегрировать новые приложения и технологии.
ИТ быстро меняются, но некоторые вещи, такие как пакетная обработка, остаются неизменными.
Готовы увидеть, как мы упрощаем автоматизацию рабочих нагрузок?
Запланируйте демонстрацию, чтобы посмотреть, как наши специалисты выполняют задания в ActiveBatch, соответствующие вашим вариантам использования. Получите ответы на свои вопросы и узнайте, насколько легко создавать и поддерживать рабочие места в ActiveBatch
Пакетная, потоковая и микропакетная обработка: шпаргалка
Достигли ли вы предела возможностей реляционной базы данных? Выполните самодиагностику по этим 5 контрольным признакам, что вы переросли свое хранилище данных.
Цифровая эпоха предоставила предприятиям множество новых возможностей для оценки своей деятельности. Прошли те времена, когда таблицы базы данных обновлялись вручную: современные цифровые системы способны фиксировать мельчайшие детали взаимодействия пользователей с приложениями, подключенными устройствами и цифровыми системами.
Поскольку цифровые данные генерируются огромными темпами, разработчики и аналитики имеют широкий спектр возможностей, когда дело доходит до ввода данных в действие и их подготовки для аналитики и машинного обучения.
Один из фундаментальных вопросов, которые вам нужно задать при планировании архитектуры данных, — это вопрос о пакетной обработке и потоковой обработке : обрабатываете ли вы данные по мере их поступления, в реальном времени или почти в реальном времени, или вы ждете данные для накопления перед выполнением задания ETL? Это руководство предназначено для того, чтобы дать вам общий обзор соображений, которые вы должны учитывать при принятии такого решения.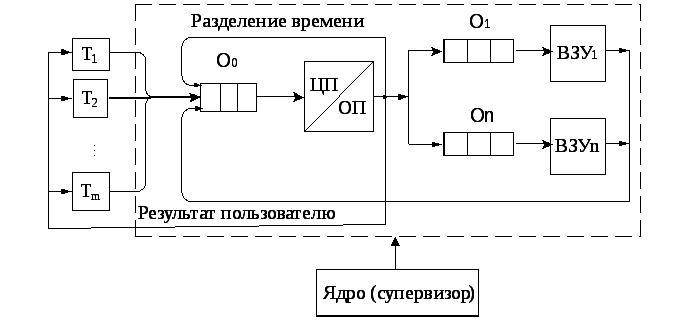 Мы также включили некоторые дополнительные ресурсы, если вы хотите погрузиться глубже.
Мы также включили некоторые дополнительные ресурсы, если вы хотите погрузиться глубже.
Пакетная обработка
Что такое пакетная обработка?
При пакетной обработке мы ждем, пока определенный объем необработанных данных «накапливается», прежде чем запускать задание ETL. Обычно это означает, что данные имеют возраст от часа до нескольких дней, прежде чем они будут доступны для анализа. Пакетные задания ETL обычно запускаются по заданному расписанию (например, каждые 24 часа) или, в некоторых случаях, когда объем данных достигает определенного порога.
Когда использовать пакетную обработку?
По определению, пакетная обработка влечет за собой задержки между временем появления данных на уровне хранения и временем их доступности в инструментах аналитики или отчетности.Однако это не обязательно серьезная проблема, и мы можем принять эти задержки, потому что мы предпочитаем работать с фреймворками пакетной обработки.
Например, если мы пытаемся проанализировать корреляцию между продлением лицензий SaaS и обращениями в службу поддержки, мы можем захотеть объединить таблицу из нашей CRM с таблицей из нашей системы продажи билетов.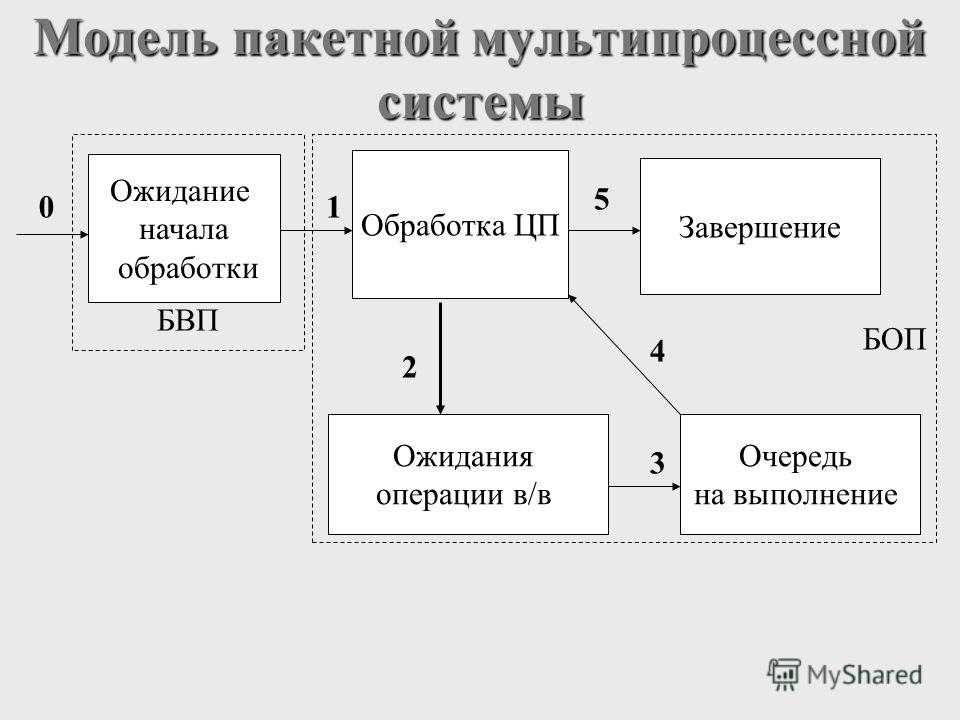 Если это соединение происходит один раз в день, а не во второй раз, когда заявка разрешена, это, вероятно, не будет иметь большого значения.
Если это соединение происходит один раз в день, а не во второй раз, когда заявка разрешена, это, вероятно, не будет иметь большого значения.
В общем, вам следует склоняться к пакетной обработке, когда:
- Свежесть данных не является критически важной проблемой
- Вы работаете с большими наборами данных и выполняете сложный алгоритм, для которого
- требуется доступ ко всему пакету — е.g., сортировка всего набора данных
- Вы получаете доступ к данным партиями, а не потоками
- При объединении таблиц в реляционных базах данных
Инструменты и платформы пакетной обработки
- Фреймворки Hadoop с открытым исходным кодом для таких как Spark и MapReduce — популярный выбор для обработки больших данных.
- Для небольших наборов данных и данных приложений вы можете использовать пакетные инструменты ETL, такие как Informatica и Alteryx
- Реляционные базы данных, такие как Amazon Redshift и Google BigQuery
Требуется вдохновение на как построить архитектуру больших данных? Посмотрите эти примеры озер данных . Хотите упростить конвейеры ETL с помощью единой платформы самообслуживания для пакетной и потоковой обработки? Попробуйте Upsolver сегодня .
Хотите упростить конвейеры ETL с помощью единой платформы самообслуживания для пакетной и потоковой обработки? Попробуйте Upsolver сегодня .
Потоковая обработка
Что такое потоковая обработка?
При потоковой обработке мы обрабатываем данные, как только они поступают на уровень хранения — что часто также очень близко ко времени их создания (хотя это не всегда так). Обычно это происходит в субсекундных таймфреймах, так что для конечного пользователя обработка происходит в режиме реального времени.Эти операции обычно не имеют состояния или могут сохранять только «небольшое» состояние, поэтому обычно включают относительно простое преобразование или вычисление.
Когда использовать потоковую обработку
Хотя потоковая обработка и обработка в реальном времени не обязательно являются синонимами, мы будем использовать потоковую обработку, когда нам нужно анализировать или обслуживать данные как можно ближе к тому моменту, когда мы их получим .
Примеры сценариев , в которых актуальность данных чрезвычайно важна, могут включать рекламу в реальном времени, онлайн-выводы в машинном обучении или обнаружение мошенничества.В этих случаях у нас есть системы, управляемые данными, которые должны принять решение за доли секунды: какое объявление показывать? Одобряем ли мы эту сделку? Мы бы использовали потоковую обработку, чтобы быстро получить доступ к данным, выполнить наши вычисления и получить результат.
Признаки правильности потоковой обработки :
- Данные генерируются в непрерывном потоке и поступают с высокой скоростью
- Субсекундная задержка имеет решающее значение
Инструменты и фреймворки потоковой обработки
Потоковая обработка и микропакетная обработка часто используется как синоним, а такие фреймворки, как Spark Streaming, фактически обрабатывают данные микропакетами.Тем не менее, есть несколько чистых инструментов обработки потоков, таких как Confluent KSQL , который обрабатывает данные непосредственно в потоке Kafka, а также Apache Flink и Apache Flume .
Микропакетная обработка
Что такое микропакетная обработка?
При микропакетной обработке мы запускаем пакетные процессы для гораздо меньших скоплений данных — обычно данных объемом менее минуты. Это означает, что данные доступны почти в реальном времени. На практике существует небольшая разница между микропакетированием и потоковой обработкой, и эти термины часто используются взаимозаменяемо в описаниях архитектуры данных и описаниях программной платформы.
Когда использовать микропакетную обработку
Микропакетная обработка полезна, когда нам нужны очень свежих данных, но не обязательно в реальном времени — это означает, что мы не можем ждать час или день пакетная обработка для запуска, но нам также не нужно знать, что произошло за последние несколько секунд.
Примеры сценариев могут включать веб-аналитику (поток кликов) или поведение пользователей. Если крупный сайт электронной коммерции вносит серьезные изменения в свой пользовательский интерфейс, аналитики хотели бы знать, как это почти сразу же повлияет на покупательское поведение, потому что падение коэффициента конверсии может привести к значительным потерям дохода.Однако, хотя дневная задержка в данном случае определенно слишком велика, минутная задержка не должна быть проблемой, что делает микропакетную обработку хорошим выбором.
Если крупный сайт электронной коммерции вносит серьезные изменения в свой пользовательский интерфейс, аналитики хотели бы знать, как это почти сразу же повлияет на покупательское поведение, потому что падение коэффициента конверсии может привести к значительным потерям дохода.Однако, хотя дневная задержка в данном случае определенно слишком велика, минутная задержка не должна быть проблемой, что делает микропакетную обработку хорошим выбором.
Инструменты и фреймворки для микропакетной обработки
- Apache Spark Streaming самая популярная платформа с открытым исходным кодом для микропакетной обработки.
- Vertica предлагает поддержку микропакетов.
Дополнительные ресурсы и дополнительная литература
Выше приведены общие рекомендации по определению, когда использовать пакетную или потоковую обработку.Тем не менее, каждая из этих тем требует дальнейших исследований сама по себе. Чтобы глубже разобраться в методах обработки данных, вы можете ознакомиться с некоторыми из следующих ресурсов:
Upsolver: Streaming-first ETL Platform
Одной из основных проблем при работе с большими потоками данных является необходимость оркестровки нескольких систем. для пакетной и потоковой обработки, что часто приводит к сложным технологическим стекам, которые сложно поддерживать и управлять.
для пакетной и потоковой обработки, что часто приводит к сложным технологическим стекам, которые сложно поддерживать и управлять.
Независимо от того, создаете ли вы архитектуру больших данных или хотите оптимизировать потоки ETL, Upsolver предоставляет комплексную платформу самообслуживания, которая объединяет пакетную, микропакетную и потоковую обработку и позволяет разработчикам и аналитикам легко сочетать потоковую и историческую большое количество данных.Чтобы узнать, как это работает, ознакомьтесь с нашим техническим официальным документом.
API пакетной обработки
API пакетной обработки доступен только для корпоративных пользователей. Если у вас нет корпоративной учетной записи и вы хотите попробовать ее, свяжитесь с нами для получения специального предложения. В настоящее время он поддерживается только в развертывании EU-Central-1 (Франкфурт).
API пакетной обработки (или сокращенно «пакетный API») позволяет запрашивать данные для больших областей и / или более длительных периодов времени.
Это асинхронная служба REST. Это означает, что данные не будут немедленно возвращены в ответе на запрос, а будут доставлены в ваше объектное хранилище, которое необходимо указать в запросе (например, сегмент S3, см. Настройки сегмента AWS S3 ниже). Результаты обработки будут разделены на плитки, как описано ниже.
Чтобы узнать больше о том, как пакетную обработку можно использовать для создания огромных мозаик или для улучшения ваших алгоритмов, прочтите следующие сообщения в блоге:
API пакетной обработки поставляется с набором REST API, которые поддерживают выполнение различных рабочих процессов.На диаграмме ниже показаны все возможные статусы запроса на пакетную обработку ( СОЗДАН , АНАЛИЗ , АНАЛИЗ_DONE , ОБРАБОТКА , ВЫПОЛНЕНА , СБОЙ ) и действия пользователя ( ANALYZE , ANALYZE ) CANCEL ), которые запускают переходы между ними.
Рабочий процесс запускается, когда пользователь отправляет новый запрос на пакетную обработку. На этом этапе система:
На этом этапе система:
- создает новый запрос пакетной обработки со статусом
СОЗДАН, - проверяет вводимые пользователем данные, а
- возвращает приблизительное количество выходных плиток, которые будут обработаны.
Затем пользователь может решить, запросить ли дополнительный анализ запроса, начать обработку или отменить запрос. При запросе дополнительного анализа:
- статус запроса меняется на
ANALYZING, - проверяется evalscript,
- создается список необходимых фрагментов, а
- оценивается стоимость запроса, т.е.е. предполагаемое количество блоков обработки (PU), необходимых для запрошенной обработки.
Обратите внимание, что в случае мозаики
ORBITилиTILEоценка стоимости может быть значительно неточной, как описано ниже. - После завершения анализа статус запроса меняется на
ANALYSIS_DONE.
Если пользователь выбирает непосредственный запуск обработки, система по-прежнему выполняет анализ, но когда анализ завершен, он автоматически запускается с обработки. Для простоты это не показано явно на диаграмме.
Для простоты это не показано явно на диаграмме.
Теперь пользователь может запросить список плиток для своего запроса, начать обработку или отменить запрос. Когда пользователь начинает обработку:
- оценочное количество PU зарезервировано,
- статус запроса меняется на
ОБРАБОТКА(это может занять некоторое время), - начинается обработка.
Когда обработка завершается, статус запроса изменяется на:
-
FAILED, когда все плитки не удалось обработать, -
PARTIAL, когда некоторые плитки были обработаны, а некоторые не удалось, -
DONEкогда все плитки были обработаны.
Хотя процесс имеет встроенную отказоустойчивость, иногда обработка мозаики может завершаться ошибкой. Повторная обработка таких плиток FAILED возможна по запросу
повторная обработка каждого фрагмента и повторный запуск обработки этого запроса.
Пользователь может отменить запрос в любое время. Однако:
Однако:
- , если статус
АНАЛИЗ, анализ будет завершен, - , если статус
ОБРАБОТКА, все плитки, которые были обработаны или обрабатываются в этот момент, оплачиваются.Остальные PU возвращаются пользователю.
Устаревшие запросы будут удалены через некоторое время. В частности, будут удалены следующие запросы:
- неудачных запросов (статус запроса
FAILED), - запросов, которые были созданы, но так и не были запущены (статусы запросов
CREATED,ANALYSIS_DONE), - успешных запросов (статусы запросов
ВЫПОЛНЕНОиЧАСТИЧНО), для которых не требовалось добавлять результаты в ваши коллекции.Обратите внимание, что будут удалены только сами такие запросы, а результат запросов (созданные изображения) останется под вашим контролем в вашей корзине S3.
Смета, представленная на этапе анализа, основана на правилах расчета единиц обработки. Он принимает во внимание количество выходных пикселей, количество входных полос и выходной формат. Однако для мозаики
Он принимает во внимание количество выходных пикселей, количество входных полос и выходной формат. Однако для мозаики ORBIT или TILE количество выборок данных (то есть количество наблюдений, доступных в запрошенном временном диапазоне) не может быть точно рассчитано во время анализа.Таким образом, наша смета расходов основана на предположении, что один образец данных доступен каждые три дня в пределах запрошенного диапазона времени.
Например, мы предполагаем 10 доступных выборок данных в период с 1.1.2021 по 31.1.2021. Если вы запрашиваете пакетную обработку большего / меньшего количества выборок данных, фактическая стоимость будет пропорционально выше / ниже.
Фактические затраты могут значительно отличаться от оценки, если:
- количество выборок данных в вашем сценарии evalscript уменьшено на
функций preProcessScenes/filterScenesили с помощью таких фильтров, какmaxCloudCoverage.Фактическая стоимость будет ниже сметы.
- ваш AOI включает большие области без данных, например при запросе данных Sentinel-2 над океаном. Фактическая стоимость будет ниже сметы.
- вы запрашиваете обработку коллекций данных с периодом повторного посещения короче / дольше трех дней (например, ваша коллекция BYOC). Фактическая стоимость будет пропорционально выше / ниже сметы. Период повторного посещения также зависит от выбранного AOI, например фактические затраты на обработку данных Sentinel-2 вблизи экватора / в высоких широтах будут ниже / выше расчетных.

Если вы знаете, сколько выборок данных на пиксель будет обработано, вы можете настроить оценку самостоятельно. Например, если вы запрашиваете обработку данных, которые доступны ежедневно, стоимость будет в 3 раза выше нашей оценки.
Обратите внимание, что при оценке затрат не учитывает коэффициент умножения 1/3 для пакетной обработки. Фактические затраты будут в 3 раза ниже сметы.
Для более эффективной обработки мы разделяем интересующую область на тайлы и обрабатываем каждый тайл отдельно.В то время как процесс API использует сетки, которые идут вместе с каждым источником данных для обработки данных, пакетный API использует одну из предопределенных мозаичных сеток. Предопределенные тайловые сетки основаны на тайлинге Sentinel-2 в проекции UTM / WGS84 с некоторыми корректировками:
- Ширина и высота тайлов в исходной сетке Sentinel 2 составляет 100 км, в то время как ширина и высота тайлов в наших сетках равны приведено в таблице ниже.
- Все повторяющиеся плитки (т. Е.полностью перекрытые плитки) удаляются.
Все доступные тайловые сетки можно запросить с помощью ( ПРИМЕЧАНИЕ: для запуска этого примера вам необходимо сначала создать клиент OAuth, как описано здесь ):
url = "https: //services.sentinel- hub.com/api/v1/batch/tilinggrids/ "
response = oauth.request (" GET ", url)
response.json ()
Это вернет список доступных сеток и информацию о размер плитки и доступные разрешения для каждой сетки.В настоящее время доступны следующие сетки:
| имя | id | ширина плитки | высота плитки | разрешения | скачать сетку [zip с файлом shp] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 20 км сетка 2004023 905 м | 20040 м | 10 м, 20 м, 60 м | 20-километровая сетка | ||||||||
| 10-километровая сетка | 1 | 10000 м | 10000 м | 10 м, 20 м | 10-километровая сетка | 905Сетка 100 км | 2 | 100080 м | 100080 м | 60 м, 120 м, 240 м, 360 м | Сетка 100 км |
| WGS84 Сетка 1 градус | 3 | 1 ° 1 ° | 0.0001 °, 0,0002 ° | WGS84 1 градусная сетка |
Чтобы использовать сетку s2gm с разрешением 60 м, например, укажите id и разрешение параметры объекта tilingGrid при создании нового пакетного запроса ( см. пример полного запроса) как:
{
...
"tilingGrid": {
"id": 0,
"разрешение": 60.0
},
...
}
Свяжитесь с нами, если вы хотите использовать любую другую сетку для обработки.
Результаты пакетной обработки будут сохранены в хранилище объектов. По умолчанию результаты будут организованы в подпапки, где будет создана одна подпапка для каждой плитки. Каждая подпапка может содержать одно или несколько изображений в зависимости от того, сколько выходных данных было определено в сценарии проверки запроса. Например:
Вы также можете настроить структуру подпапок, как описано в разделе выходной параметр в справочнике по BATCH API.
В настоящее время поддерживаются форматы выходных изображений png, jpeg и GeoTIFF.
Результаты пакетной обработки будут в проекции UTM / WGS84. Каждая часть aoi доставляется в зону UTM, с которой она пересекается. Другими словами, если ваша область интереса (aoi) пересекается с большим количеством зон UTM, результаты будут доставлены в виде плиток в разных зонах UTM (и, следовательно, в разных CRS).
Корзина, в которую будут доставлены результаты, должна находиться в регионе eu-central-1 (Франкфурт).
Sentinel Hub требуется полный доступ к корзине. Для этого обновите политику сегмента, включив в него следующий оператор (не забудьте заменить на свое фактическое имя сегмента):
{
"Версия": "2012-10-17 »,
« Заявление »: [
{
« Sid »:« Разрешения Sentinel Hub »,
« Эффект »:« Разрешить »,
« Принципал »: {
« AWS »:« arn: aws: iam :: 614251495211: root "
},
" Action ": [
" s3: * "
],
" Resource ": [
" arn: aws: s3 ::: < bucket_name> ",
" arn: aws: s3 :::
/ * " ]
}
]
}
Пример рабочего процесса пакетной обработки
5 причин, почему Spark Streaming пакетная обработка обработка потоков данных не является потоковой обработкой - SQLstream
Несомненно, существует несколько подходов к тому, как системы работают с данными в реальном времени, прежде чем они будут сохранены в базе данных.Например, две из наиболее распространенных платформ с открытым исходным кодом для этого - Apache Storm и Apache Spark (с его фреймворком Spark Streaming), и обе используют совершенно другой подход к обработке потоков данных. Storm, как и Guavus SQLstream, IBM InfoSphere Streams и многие другие, являются настоящими механизмами обработки потока записи за записью. Другие, такие как Apache Spark, используют другой подход и собирают события вместе для обработки в пакетах. Я суммировал здесь основные соображения при выборе наиболее подходящей парадигмы.
Сравнение потоковой обработки №1 и пакетной обработки потоков данных
Есть два основных атрибута обработки потока данных. Во-первых, каждая запись в системе должна иметь метку времени, которая в 99% случаев является временем создания данных. Во-вторых, каждая запись обрабатывается по мере поступления. Эти два атрибута обеспечивают систему, которая может реагировать на содержимое каждой записи и может коррелировать между несколькими записями с течением времени, даже с задержкой до миллисекунды.Напротив, такие подходы, как Spark Streaming, обрабатывают потоки данных в пакетном режиме, где каждый пакет содержит набор событий, поступивших в течение периода пакета (независимо от того, когда данные были фактически созданы). Это нормально для некоторых приложений, таких как простые подсчеты и ETL в Hadoop, но отсутствие настоящих процессов записи за записью делает невозможной потоковую обработку и анализ временных рядов.
# 2 Данные, поступающие не по расписанию, являются проблемой для пакетной обработки
Обработка данных в реальном мире - занятие грязное.Данные часто имеют низкое качество, записи могут отсутствовать, а потоки поступают с данными вне временного порядка (создания). Данные из нескольких удаленных источников могут генерироваться одновременно, но из-за сетевых или других проблем некоторые потоки могут задерживаться. Следствием хранимой пакетной обработки потоков данных является то, что эти факторы реального времени не могут быть легко устранены, что делает невозможным или в лучшем случае дорогостоящим (вычислительные ресурсы и, следовательно, производительность) обнаружение недостающих данных, пробелов в данных, исправление данных вне временного порядка и т. .Это простая проблема, которую необходимо решить для платформы обработки потока записи за записью, где каждая запись имеет свою собственную метку времени и обрабатывается индивидуально.
# 3 Длина пакета ограничивает аналитику на основе окна
Любая система, использующая пакетную обработку потоков данных, ограничивает степень детализации ответа длиной пакета. Оконные операции можно моделировать путем многократного повторения серии микропакетов, почти так же, как статические запросы работают с сохраненными данными.Однако это дорого с точки зрения ресурсов обработки и увеличивает накладные расходы на вычисления. И обработка по-прежнему ограничивается временем поступления данных (а не временем, когда данные были созданы).
# 4 Spark утверждает, что он быстрее, чем Storm, но все еще имеет ограниченную производительность
Архитектура выполненияSpark Streaming на основе Java или Scala, как утверждается, в 4-8 раз быстрее, чем Apache Storm при использовании теста WordCount. Однако в наши дни Apache Storm предлагает ограниченную производительность на сервер по стандартам потоковой обработки, хотя масштабируется на большое количество серверов для повышения общей производительности системы.(Это может сделать большие системы дорогими как с точки зрения затрат на сервер, питание и охлаждение, так и с точки зрения дополнительной сложности распределенной системы.) Дело в том, что производительность Spark Streaming может быть улучшена за счет использования больших пакетов, что может объяснить производительность увеличивается, но большие пакеты все дальше уходят от обработки в реальном времени в сторону сохраненного пакетного режима и усугубляют проблемы потоковой обработки и аналитики в реальном времени.
# 5 Написание операций потоковой обработки с нуля непросто
Пакетные платформы, такие как Spark Streaming, обычно предлагают ограниченные библиотеки потоковых функций, которые вызываются программно для выполнения агрегации и подсчета поступающих данных.Например, для разработки приложения потоковой аналитики на Spark Streaming требуется написать код на Java или Scala. Обработка потоков данных - это другая парадигма, и, более того, Java типично в 50 раз менее компактна, чем, скажем, SQL - требуется значительно больше кода. Java и Scala требуют значительной сборки мусора, что особенно неэффективно и проблематично для обработки в памяти.
Пакетная обработка — Drone2Map для ArcGIS Help
Пакетная обработка позволяет создавать несколько заданий обработки и позволять Drone2Map обрабатывать их последовательно.Это избавляет пользователя от необходимости следить за завершением проекта перед запуском другого проекта. Вы можете запустить несколько заданий, позволить им работать на ночь, а утром просмотреть свои результаты.
Создать новое задание пакетной обработки
Чтобы начать пакетную обработку ваших проектов, вы можете открыть существующее задание пакетной обработки или создать новое задание пакетной обработки. Используйте настройки приложения, чтобы установить место по умолчанию для хранения ваших пакетных заданий. Чтобы создать новое пакетное задание, выполните следующие действия:
- Щелкните значок Пакетная обработка на главной ленте.
- В окне пакетной обработки оставьте расположение папки пакета по умолчанию или нажмите кнопку «Обзор», чтобы выбрать новое расположение для сохранения пакетного задания.
- Дайте название своему заданию пакетной обработки.
- Щелкните "Создать".
Открыть существующее задание пакетной обработки
При создании задания пакетной обработки папка пакетного задания и командный файл bd2m создаются в указанном месте. Чтобы открыть существующее задание, выполните следующие действия:
- Щелкните значок Пакетная обработка на главной ленте.
- В окне пакетной обработки щелкните Открыть.
- Перейдите к файлу пакетного задания (.bd2m) и нажмите «Открыть».
Добавить проект в пакетное задание
После открытия пакетного задания вы можете добавлять проекты в пакетное задание. Выполните следующие шаги, чтобы создать новые проекты для добавления в пакетное задание:
- В открытом окне пакетной обработки щелкните вкладку «Проект» в верхнем левом углу приложения и следуйте инструкциям по созданию нового проекта.
- Задайте параметры обработки. При необходимости добавьте свои опорные точки и определите область отсечения.
- Когда ваш проект будет подготовлен к обработке, нажмите «Текущий» под заголовком «Добавить проект» на панели «Пакетная обработка». Предупреждение сообщает, что проект будет закрыт и добавлен в пакетную обработку. Щелкните Да, чтобы продолжить, или Нет, чтобы отменить.
- Повторите шаги 1–3, чтобы продолжить добавление проектов в пакетное задание.
Чтобы добавить существующие проекты в задание, нажмите кнопку «Обзор» под заголовком «Добавить проект» на панели «Пакетная обработка».Перейдите к файлу d2m проекта, выберите его и нажмите «Открыть».
Управление проектами
По мере добавления проектов в список заданий окно пакетной обработки обновляется с указанием количества проектов и общего количества изображений. Проекты перечислены в порядке добавления. Измените порядок проектов, щелкнув маркер слева от имени проекта и перетащив его вверх или вниз в нужное положение. При щелчке по проекту в списке карта приближается к местоположению проекта.
Для каждого проекта сохраняется следующая информация:
- Изображения - отображает количество изображений в проекте.
- Статус - отображает текущий статус отдельного проекта.
- В очереди - проект ожидает выполнения.
- Выполняется - проект в настоящее время обрабатывается.
- Завершено - Проект завершен.
- Остановлено - проект начал обработку, однако пользователь решил остановить обработку.
- Failed - проект начал обработку, однако во время обработки произошла ошибка.
- Цвет - установка цвета посадочного места проекта на карте.Выберите уникальный цвет для каждого проекта, чтобы легко идентифицировать каждый проект на карте. Граница посадочного места меняет цвет в зависимости от статуса проекта.
- В очереди - отображает выбранный цвет посадочного места.
- Выполняется - в работающем проекте посадочное место отображается желтой рамкой.
- Завершено. Завершенные проекты выделяются зеленой рамкой вокруг контура.
- Остановлен или сбой - возврат к исходному цвету посадочного места.
Параметры проекта
Параметры проекта позволяют взаимодействовать с проектами пакетных заданий.
- Открыть проект - открывает выбранный проект и масштабирует отображение карты до экстента проекта. Вы можете открыть проект в любой момент во время обработки. Если проект открыт, открытие второго проекта закроет текущий проект. У вас может быть открыт только один проект одновременно.
- Параметры обработки - открывает окно параметров обработки для выбранного проекта, позволяя настроить параметры обработки для выбранного проекта, не открывая проект.
- Отчет об обработке - открывает отчет об обработке для выбранного проекта.Отчет об обработке доступен, когда проект достигает статуса завершенного.
- Удалить - удаляет выбранный проект из пакетного задания. Вы можете удалить проект только тогда, когда обработка остановлена.
Закрыть проект
Есть несколько способов закрыть открытый проект во время пакетной обработки.
- Нажмите кнопку «Закрыть проект» на главной ленте. Щелкните Да, чтобы подтвердить закрытие текущего открытого проекта, или Нет, чтобы отменить.
- Выберите открытый проект в списке пакетной обработки.В разделе «Добавить проект» нажмите «Обновить». Щелкните Да, чтобы подтвердить закрытие проекта, или Нет, чтобы отменить.
Карта масштабируется до глобального экстента. Щелкните проект в списке пакетов, чтобы увеличить его до экстента.
Выполнить пакетное задание
После того, как ваши проекты загружены, расположены в желаемом порядке и установлены параметры обработки, нажмите «Пуск», чтобы выполнить задание пакетной обработки. Статус первого проекта в списке будет обновлен до текущего. Чтобы остановить задание пакетной обработки, нажмите «Остановить».Если вы остановите, а затем повторно запустите задание пакетной обработки, обработка начнется с начального шага первого проекта в списке. Он не возобновится с того момента, когда вы остановили обработку.
Чтобы закрыть задание пакетной обработки, оно должно быть либо завершено, либо вы можете остановить обработку вручную. Когда обработка остановлена, нажмите «Закрыть» в нижнем левом углу панели «Пакетная обработка».
Отзыв по этой теме?
Разница между пакетной обработкой и потоковой обработкой
Разница между пакетной обработкой и потоковой обработкой
Необходимое условие - типы операционных систем
1.Пакетная обработка:
Пакетная обработка означает обработку большого объема данных в пакетном режиме в течение определенного промежутка времени. Он обрабатывает сразу большой объем данных. Пакетная обработка используется, когда размер данных известен и конечен. Обработка данных занимает немного больше времени. Для решения проблем требуется специальный персонал. Пакетный процессор обрабатывает данные за несколько проходов. Когда данные собираются сверхурочно и аналогичные данные группируются / группируются вместе, тогда в этом случае используется пакетная обработка.
Проблемы с пакетной обработкой:
- Отладка этих систем сложна, так как для исправления ошибки требуется специализированный профессионал.
- Программное обеспечение и обучение требуют больших затрат изначально только для понимания пакетного планирования, запуска, уведомления и т. Д.
2. Потоковая обработка:
Потоковая обработка означает обработку непрерывного потока данных сразу после его создания. Он анализирует потоковые данные в реальном времени.Потоковая обработка используется, когда размер данных неизвестен, бесконечен и непрерывен. Обработка данных занимает несколько секунд или миллисекунд. При потоковой обработке скорость вывода данных такая же, как скорость ввода данных. Потоковый процессор обрабатывает данные за несколько проходов. Когда поток данных является непрерывным и требует немедленного ответа, в этом случае используется потоковая обработка.
Проблемы с потоковой обработкой:
- Скорость ввода и вывода данных иногда создает проблемы.
- Справиться с огромным объемом данных и немедленным ответом.
Разница между пакетной обработкой и потоковой обработкой:
| S. No. | ПАКЕТНАЯ ОБРАБОТКА | ОБРАБОТКА ПОТОКА |
|---|---|---|
| 01. | Пакетная обработка - это пакетная обработка большого объема данных в течение определенного промежутка времени. | Потоковая обработка означает обработку непрерывного потока данных сразу после его создания. |
| 02. | При пакетной обработке обрабатываются все большие объемы данных одновременно. | Stream Processing анализирует потоковые данные в реальном времени. |
| 04. | В пакетной обработке размер данных известен и конечен. | При потоковой обработке размер данных заранее неизвестен и бесконечен. |
| 05. | При пакетной обработке данные обрабатываются за несколько проходов. | При потоковой обработке данные обычно обрабатываются за несколько проходов. |
| 06. | Пакетный процессор обрабатывает данные дольше. | Потоковому процессору требуется несколько секунд или миллисекунд для обработки данных. |
| 07. | При пакетной обработке входной граф статичен. | При потоковой обработке входной граф является динамическим. |
| 08. | При этой обработке данные анализируются на снимке. | При этой обработке данные анализируются непрерывно. |
| 09. | При пакетной обработке ответ предоставляется после завершения задания. | При потоковой обработке ответ предоставляется немедленно. |
| 10. | Примеры - это платформы распределенного программирования, такие как MapReduce, Spark, GraphX и т. Д. | Примерами являются платформы программирования, такие как Spark Streaming и S4 (Простая масштабируемая потоковая система) и т. Д. |
| 11. | Пакетная обработка используется в системах расчета заработной платы и выставления счетов, в системах пищевой промышленности и т. Д. | Потоковая обработка используется на фондовом рынке, в транзакциях электронной коммерции, в социальных сетях и т. Д. |
Вниманию читателя! Не прекращайте учиться сейчас. Получите все важные концепции теории CS для собеседований SDE с помощью курса CS Theory Course по приемлемой для студентов цене и будьте готовы к работе в отрасли.
20 лучших заданий по пакетной обработке, сейчас нанимают
ЧТО ТАКОЕ ПЕЧЕНЬЕ?
Файл cookie - это небольшой файл с буквами и цифрами, который мы хранить в браузере или на жестком диске вашего компьютера, если вы согласны.Файлы cookie содержат информацию, которая передается на ваш жесткий диск компьютера.
КАКИЕ ВИДЫ cookie-файлов МЫ ИСПОЛЬЗУЕМ?
Мы используем два типа файлов cookie на нашем веб-сайте:
«Сеансовые файлы cookie»
Это временные файлы cookie,
которые существуют только в период, когда вы заходите на сайт (или более
строго, пока вы не закроете браузер после доступа к сайту).
Сессионные файлы cookie помогают нашему веб-сайту запоминать то, что вы выбрали на
предыдущая страница, что позволяет избежать повторного ввода информации.На
на нашем веб-сайте эти файлы cookie не содержат личной информации, и
не могут быть использованы для вашей идентификации.
«Постоянные файлы cookie»
Эти файлы cookie остаются включенными
ваше устройство после посещения нашего веб-сайта. Эти файлы cookie помогают
нам, чтобы идентифицировать вас как уникального посетителя (путем сохранения случайным образом
сгенерированный номер).
ПОЧЕМУ МЫ ИСПОЛЬЗУЕМ файлы cookie?
Для адаптации нашего веб-сайта к вашим потребности, мы используем различные технологии, включая файлы cookie, которые позволяют мы, чтобы отличать вас от других пользователей нашего сайта.
Мы используем файлы cookie: для распознавания и подсчета количества
посетители и страницы или различные части страницы, которые они посетили
наш сайт; Чтобы увидеть, как посетители перемещаются по сайту, когда они
используя его, например, мы используем Google Analytics, популярный веб-сайт
служба аналитики, предоставляемая Google Inc., Google Analytics использует
файлы cookie, которые помогают нам анализировать, как посетители используют наш сайт. Это помогает
нам, чтобы улучшить работу нашего веб-сайта, например, путем обеспечения
что посетители легко находят то, что ищут.Найдите нашу
подробнее о том, как эти файлы cookie используются на Сайт конфиденциальности Google.
Для улучшения и отслеживания рекламы предлагаем
наши посетители. Мы также используем Google DoubleClick, который является одним из
ведущий мировой поставщик решений для управления рекламой и ее обслуживания.
Как и большинство веб-сайтов и поисковых систем, Google использует файлы cookie для того, чтобы
чтобы обеспечить удобство работы пользователей и показывать релевантную рекламу. Находить
Чтобы узнать больше о том, как используются эти файлы cookie, нажмите здесь.К
представить нашим посетителям наиболее подходящие рекламные баннеры
и контент, основанный на интересах и активности наших посетителей, мы, для
пример использования Yahoo! Search Marketing, инструмент поискового маркетинга Yahoo!
(включая Overture Search Services (Ireland) Limited). От имени
Dice Careers Limited, Yahoo! Search Marketing будет использовать это
информация, которая поможет нам отслеживать эффективность наших онлайн-
маркетинговые кампании. Для получения дополнительной информации о том, как Yahoo! использует
информация, представленная на Yahoo! Веб-сайты рекламных решений,
пожалуйста, прочтите Yahoo! Политика конфиденциальности рекламных решений.
Таким образом, с помощью файлов cookie мы можем улучшить ваш опыт
когда вы просматриваете наш веб-сайт и позволяете нам постоянно улучшать наши
сайт и наши услуги для вас. Наши файлы cookie были установлены в наших
браузера, и мы предположим, что вы согласны с ними, через ваш непрерывный
использование нашего веб-сайта. Вы можете отключить определенные файлы cookie, как указано
ниже. Если вы отключите эти файлы cookie, мы не сможем гарантировать, как сайт
выступит за вас.
УПРАВЛЕНИЕ КУКИ
Включение файлов cookie гарантирует, что вы получите оптимального пользователя опыт работы с нашим сайтом.
Большинство браузеров автоматически принимают файлы cookie, но вы можете отключите эту функцию в любое время и настройте свой браузер на уведомление вам всякий раз, когда отправляется файл cookie. Вы можете использовать настройки своего браузера, чтобы заблокировать все или некоторые файлы cookie. Обратите внимание: если вы заблокируете все файлы cookie, возможно, вы не сможете получить доступ ко всем или частям нашего сайта.
Большинство браузеров автоматически принимают файлы cookie, но вы можете отключите эту функцию в любое время и настройте свой браузер на уведомление вам всякий раз, когда отправляется cookie.Вы можете использовать настройки своего браузера, чтобы заблокировать все или некоторые файлы cookie. Обратите внимание: если вы заблокируете все файлы cookie, возможно, вы не сможете получить доступ ко всем или частям нашего сайта.
Изменение настроек файлов cookie в разных браузеры, для удобства мы включили инструкции по изменению вашего настройки в наиболее популярных браузерах ниже:
ОТКЛЮЧИТЬСЯ ИЗ GOOGLE ДВОЙНОЙ КЛИК
Любой, кто предпочитает не использовать файлы cookie Google DoubleClick, может отказаться.Этот отказ будет относиться только к тому браузеру, который вы используются, когда вы нажимаете "Отказаться" кнопка. http://www.google.co.uk/policies/privacy/ads/
ОТКАЗАТЬСЯ ОТ YAHOO! ПОИСК-МАРКЕТИНГ
При желании вы можете отказаться от участия в Yahoo! Поиск Маркетинг с использованием информации, собираемой с помощью веб-маяков и файлов cookie за пределами Yahoo! сеть веб-сайтов. Файлы cookie должны быть включен для функции отказа.
Примечание. Этот отказ применяется к конкретному браузеру, а не чем конкретный пользователь.Поэтому вам нужно будет отказаться отдельно с каждого компьютера или браузера, который вы используете. Кроме того, Отказ применяется только к файлам cookie, используемым perf.overture.com, но не все файлы cookie, установленные overture.com.
Как проверить, включены ли файлы cookie на платформах Windows
Microsoft Internet Explorer 7, 8 и 9
1.
Выберите «Инструменты» в верхнем меню браузера, а затем выберите
«Свойства обозревателя», затем перейдите на вкладку «Конфиденциальность» 2.Убедитесь, что
ваш уровень конфиденциальности установлен на средний или ниже, что позволит
файлы cookie в вашем браузере 3. Настройки выше Средний отключают
файлы cookie
Mozilla Firefox
1. Выберите «Инструменты» наверху.
меню вашего браузера, а затем выберите "Параметры" 2. Затем выберите
Значок конфиденциальности 3. Нажмите «Файлы cookie», затем выберите «Разрешить сайтам устанавливать
cookies '
Google Chrome
1. Выберите "Инструменты" в верхнем меню.
вашего браузера, а затем выберите "Параметры" 2.Нажмите "Под
На вкладке "Капюшон" найдите раздел "Конфиденциальность" и выберите "Контент".
Настройки »3. Теперь выберите« Разрешить установку локальных данных »
Safari
1. Выберите значок шестеренки в верхнем меню.
вашего браузера, а затем выберите "Настройки" 2. Выберите "Безопасность".
и установите флажок "Блокировать сторонние и рекламные
cookies »3. Нажмите« Сохранить ». Как проверить, разрешены ли файлы cookie для Apple.
платформы Microsoft Internet Explorer 5.