
Пакетная обработка: Пакетная обработка фотографий в плагинах AKVIS
Автоматизация. Пакетная обработка файлов — Автоматизация в Photoshop
В этом уроке рассмотрим автоматизацию в Photoshop. Создание контрольного листа. Преобразование PDF-документов в PSD-документы. Макетирование изображения на листе.Пакетная обработка файлов.
Под пакетной обработкой подразумевают применение идентичных преобразований к целому ряду документов («пакету»).
Пакетная обработка необходима в том случае, если нужно обработать по одинаковому алгоритму большой объем графических файлов. Типичными примерами такой работы есть перевод большого числа файлов в другой графический формат или в другую цветовую модель, изменение размеров файлов и т.д.
Для начала необходимо создать макрос, который может сделать то, что Вам необходимо с отдельными файлами. Уже этого может быть вполне достаточно, если количество файлов к которым необходимо применить этот макрос небольшое. Но если таких файлов десятки, сотни или тысячи, то даже использование макроса в уже известном Вам плане будет нелегким однотипным делом. Здесь как раз и может помочь пакетная обработка файлов, которая сможет сама выполнить созданный Вами макрос для необходимого числа файлов.
Здесь как раз и может помочь пакетная обработка файлов, которая сможет сама выполнить созданный Вами макрос для необходимого числа файлов.
Для начала пакетной обработки множества документов с помощью одной макрокоманды необходимо выполнить команду Batch… (Пакетная обработка…) менюFile/Automate (Файл/Автоматизация). На экране появится диалоговое окно Batch (Пакетная обработка), которое позволит выбрать исходную папку, макрокоманду и целевую папку. В поле Play (Выполнить) этого диалогового окна расположены два списка, из которых производится выбор набора макрокоманд список Set и конкретной макрокоманды (список Action (Операция)).
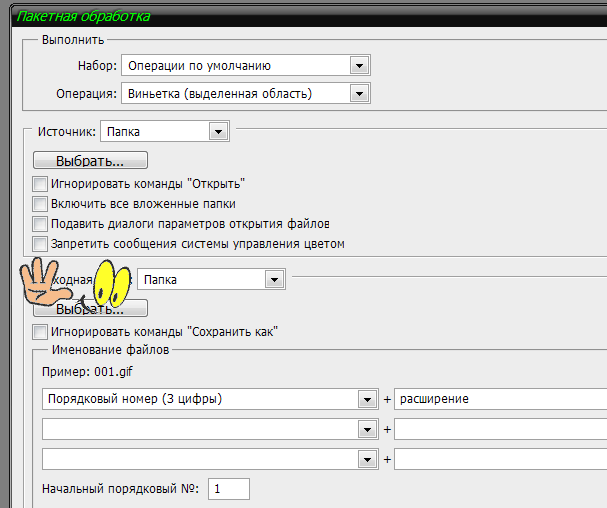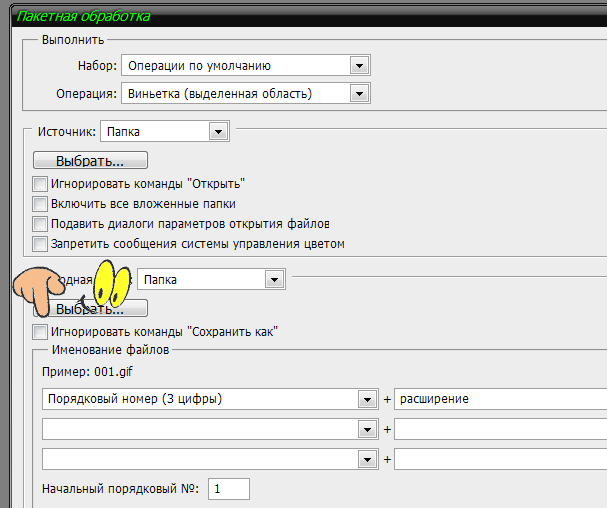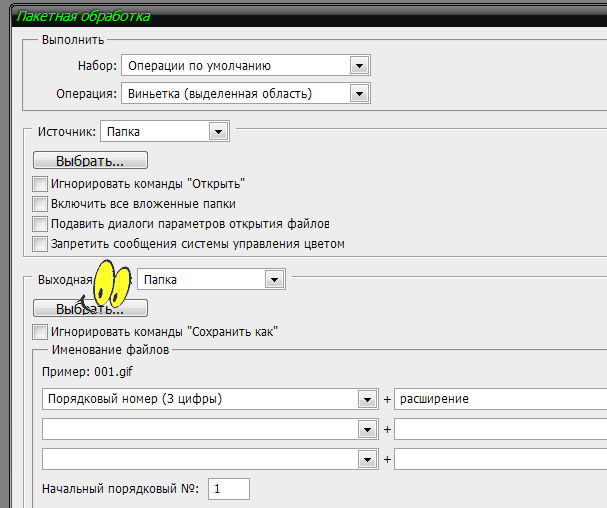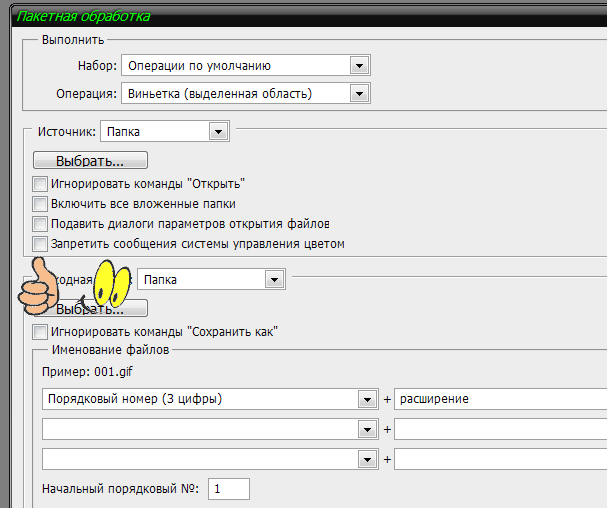
В списке поля Source: (Источник) предлагается выбор одного из четырех вариантов: Вариант Folder (Папка) позволяет с помощью кнопки Choose… (Выбрать…) определить папку-источник документов, предназначенных для пакетной обработки. Лишних документов в этой папке быть не должно. Невозможность создавать списки документов, предназначенных для пакетной обработки, существенное ограничение весьма полезной функции, поскольку нужно заводить специальную папку и переписывать туда документы для пакетной обработки.
Щелчок на кнопке Choose… (Выбрать…) поля Source: (Источник:) выводит на экран диалоговое окно Select the batch source folder (Выбрать входную папку), в котором можно определить папку с исходными документами.
Вариант Import (Импорт) позволяет получать изображения непосредственно со сканера или цифровой камеры, подключенной к компьютеру и поддерживающего интерфейс TWAIN..
Вариант Opened Files (Открытые файлы) применяет макрос ко всем открытым в данный момент файлам.
Вариант File Browser (Навигатор файлов) позволит применить выбранный Вами макрос к файлам, выбранным в File Browser.
Флажок Override Action «Open» Commands (Игнорировать команды «Сохранить в») следует установить, если необходимо предотвратить сохранение обработанных документов в папках, используемых по умолчанию в диалоговых окнах команд Save As… (Сохранить как…) и Save a Copy… (Сохранить копию…).
Флажок Include All Subdirectories (Включить все подкаталоги) позволяет обрабатывать документы, расположенные во вложенных папках.
Флажок Suppress Color Profile Warnings (Запретить вывод предупреждений цветовых профилей) отключает отображение сообщений, связанных с цветовыми профилями.
Поле Destination (Результат) служит для определения конечного назначения документов после обработки:
- Вариант None (He сохранять) оставляет файлы открытыми и не сохраняет внесенные изменения.
- Вариант Save and Close (Сохранить и закрыть) обеспечивает сохранение в текущей папке.
- Вариант Folder (Папка) позволяет определить иную папку для сохранения обработанных документов. Здесь также используется кнопка Choose… (Выбрать…) для выбора нужной папки.
При выборе варианта Folder (Папка) следует установить флажок Override Action «Save In» (Игнорировать команды «Сохранить в»), который обеспечит исключение папок, установленных по умолчанию в командах Save As… (Сохранить как…) и Save a Copy… (Сохранить копию…), в качестве мест для хранения обработанных документов.
Также при выборе варианта Folder (Папка) становится активным раздел File Naming (Наименование файлов) в котором Вы можете определить правила по которым будут задаваться имена записываемых файлов и их расширения. Можно определить до трех правил сразу. Крайне желательно, чтобы хотя бы в одном из правил было задано такое, которое могло бы дать файлу уникальное имя, чтобы не произошло замещения файлов друг другом. К таким правилиам можно отнести (filename — имя исходного файла, serial number — серийный(порядковый) номер и serial letter — серийная(порядковая) буква.)
В поле Errors вы можете определить, как будут обрабатываться ошибки, возникшие во время выполнения. Можно выбрать два варианта: Stop for Errors (Останавливаться при возникновении ошибок) — в этом случае выполнение макросов будет приостанавливаться ожидая дополнительные инструкции пользователя и Log Errors to File (Запись ошибок в файл) — в этом варианте ошибки будут записываться в отдельный файл, указанный Вами с помощью опцииSave As (Записать как. ..) в этом же разделе данного окна.
..) в этом же разделе данного окна.
Изменение цветовой модели.
Команда Conditional Mode Change… (Изменить цветовой формат…) конвертирует цветовую модель документа в соответствии с исходным цветовым режимом документа. Следует иметь в виду, что при использовании ее в макрокоманде можно не сомневаться в том, что несоответствие цветовой модели не приведет к сообщению об ошибке. В одноименном диалоговом окне в поле Source Mode (Исходный цветовой формат) представлены флажки, установка которых определяет цветовой режим документов, подлежащих конвертированию в другой цветовой режим, который выбирается из списка Target Mode (Выходной цветовой формат). Взаимному конвертированию могут подвергаться следующие режимы: Bitmap (Битовый), Grayscale (Градации серого), Duotone (Дуплекс), Indexed Color (Индексированные цве та), RGB Color (GRB), CMYK Color (CMYK), Lab Color (Lab), Multichannel (Многоканальное изображение).
Создание контрольного листа.

С помощью команды Contact Sheet… (Контрольный лист…) существует возможность в автоматическом режиме создать документ, в котором в уменьшенном виде будут представлены изображения, собранные в определенной папке. Функция эта может пригодиться художнику или дизайнеру для подачи эскизов заказчику, редактору и прочим заинтересованным лицам. В одноименном диалоговом окне в поле Source Directory (Входная папка) с помощью кнопкиChoose… (Выбрать…) можно определить папку, документы которой будут использоваться.
В разделе Document (Документ) определяются параметры нового документа: ширина (поле Width), высота (поле Height), разрешение (поле Resolution)и цветовая модель (поле Mode).
При включенной опции Flattern All Layers (Сведение всех слоев) конечный результат получается на одном фоновом слое. Если же эту опцию отключить, то все созданные миниатюры будут находиться на отдельных слоях, а все текстовые коментарии на отдельных текстовых слоях.
В разделе Thumbnails переключатели Place Across First (По строкам) и Place Down First (По столбцам) определяют порядок размещения уменьшенных изображений по строкам и колонкам, число которых устанавливается в полях Columns (Столбцов) и Rows (Строк).
И последний раздел Use Filename As Caption (Использовать имя файла, как пояснение) позволяет подписать миниатюры именами файлов. Шрифт таких подписей Вы можете выбрать в настройках Font(Шрифт) и Font Size(Размер Шрифта).
Давайте применим данный инструмент для всем хорошо знакомой папки с картинками, входящей в пакет Photoshop:
Подгонка изображения под определенные размеры.
Команда Fit Image… (Изменить размерность…) меню File/Automate (Файл/Автоматизация) служит для изменения размера изображения без изменения пропорций. В одноименном диалоговом окне следует изменить один из размеров изображения и нажать кнопку ОК (Да). В результате будет изменен размер изображения без изменения его пропорций.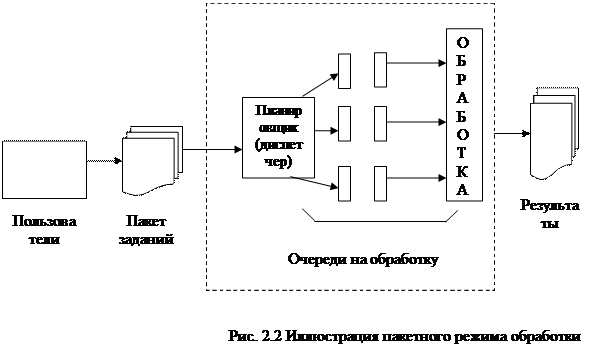 Эта команда является упрощенным вариантом команды Image Size (Размер изображения) меню Edit (Редактирование).
Эта команда является упрощенным вариантом команды Image Size (Размер изображения) меню Edit (Редактирование).
Преобразование PDF-документов в PSD-документы.
Тем, кто часто использует документы формата Adobe Acrobat (файлы с расширением .PDF) в программе Adobe Photoshop, может пригодиться команда Multi-Page PDF to PSD… (Многостраничный PFD в PSD…). Эта команда позволит конвертировать многостраничные документы в отдельные изображения формата программы Adobe Photoshop. В диалоговом окне Convert Multi-Page PDF to PSD (Преобразовать многостраничный PFD в PSD) в поле Source PDF (Входной PFD-документ) с помощью кнопки Choose… (Выбрать…) определяется документ в формате PDF, который предполагается конвертировать.
В поле Page Range (Диапазон страниц) переключатели Аll (Все) и From… То (С… по) служат для определения диапазона конвертируемых страниц исходного документа.
Поле Output Options (Выходные параметры) предназначено для установок параметров точечных изображений: разрешения (поле Resolution) и цветовой модели (поле Mode).
В разделе Destination (Место назначения) Вы указываете куда необходимо поместить результат. Установка Base Name (Основное имя) позволяет задать базовое имя к которому будут добавлены порядковые номера, начиная с «0001». Вы также можете выбрать папку Choose…, в которой будут сохраняться документы в формате программы Adobe Photoshop (файлы с расширением *.PSD).
Последняя опция Suppress Warnings позволяет игнорировать все сообщения, возникающие во время работы, и не выводить из пользователю.
Макетирование изображения на листе.
Команда Picture Package (Упаковка Изображения) позволяет сгруппировать на листе несколько копий изображения в определенном порядке. В разделе Sourse Image выбирают изображение к которому будет применена команда. Можно через команду Choose… найти нужное изображение на диске или же, включив флажок Use Frontmost Document.
В разделе Layout выбирают способ размещения копий на новом документе. Раздел Resolution определяет с каким разрешением будет выводиться изображение в документе. В поле Mode выбирают цветовой режим изображения.
Раздел Resolution определяет с каким разрешением будет выводиться изображение в документе. В поле Mode выбирают цветовой режим изображения.
Автоматическое создание Web-фотогаллереи.
Команда Web Photo Gallery… является достаточно сложной, но использовать ее очень просто. Действия этой команды позволяют преобразовать набор изображений и сформировать из них Web-страницу, на которой все эти изображения будут присутствовать, также есть возможность просматривать отдельно каждое изображение.
Обзор программы XnView — пакетная обработка веб-графики
Здравствуйте уважаемые читатели блога lessons-joomla.ru. Сейчас я расскажу вам об отличной программе XnView которая поддерживает пакетную обработку веб-графики.
В настоящее время в сети можно найти большое количество сайтов и блогов, специализирующихся на размещении графического контента (картинок, фотографий и так далее). Отличительной особенностью таких ресурсов является наличие постов, содержащих сразу несколько десятков изображений. Чтобы подготавливать графический контент в таком объеме, нужны специальные программные средства, которые позволят в той или иной степени автоматизировать весь процесс и сэкономить время вебмастера.
Чтобы подготавливать графический контент в таком объеме, нужны специальные программные средства, которые позволят в той или иной степени автоматизировать весь процесс и сэкономить время вебмастера.
Так вот, такая программа есть — это XnView. При помощи нее можно просматривать, редактировать, конвертировать изображения и делать много чего еще. Вот официальный сайт данной программы — http://www.xnview.com/en/xnview/. Здесь ее можно скачать в нескольких версиях для ПК, а также в версиях для планшетов и смартфонов. Понятно, что версии для мобильных устройств обладают значительно более урезанным функционалом. Программа является бесплатной (по крайней мере, в своей базовой комплектации – без дополнительных аддонов и плагинов). С установкой никаких проблем возникнуть не должно.
Рабочее окно программы XnView представляет собой привычный проводник файлов. Слева находится вертикальный список папок (в том числе вложенных папок), а справа – содержимое выбранной папки. Программа распознает и показывает пользователю лишь графические файлы (но можно настроить ее на показ всех файлов).
Для пакетной обработки веб-графики нам понадобятся лишь команды контекстного меню. Что бы его вызвать просто щелкните на изображении правой кнопкой мыши. Выделим три основные команды.
Конвертировать. При помощи Ctrl выделите необходимые изображения, а затем в контекстном меню выберите «Конвертировать в». Доступно 3 варианта конвертации – в JPEG, TIFF, PNG, BMP. Созданные в новом формате файлы не заменят существующие.
Пакетное переименование. Данная опция пригодится в том случае, если вы уделяете большое внимание SEO-названию изображений. К примеру, ваш пост на блоге посвящен автомобилям. В посте содержится порядка 50 фотографий машин. При этом названия фотографий состоят из каких-то случайных символов и букв. При помощи опции «Пакетное переименование» вы можете очень быстро переименовать все изображения по созданному шаблону. К примеру, шаблон будет следующим – photo_auto-##. Тогда первая картинка будет называться photo_auto-1.jpg, вторая — photo_auto-2.jpg и т.д. То есть вместо решетки будет подставляться порядковый номер файла. В специальном окошечке пакетного переименования можно увидеть список имен всех файлов (старых и новых).
При помощи опции «Пакетное переименование» вы можете очень быстро переименовать все изображения по созданному шаблону. К примеру, шаблон будет следующим – photo_auto-##. Тогда первая картинка будет называться photo_auto-1.jpg, вторая — photo_auto-2.jpg и т.д. То есть вместо решетки будет подставляться порядковый номер файла. В специальном окошечке пакетного переименования можно увидеть список имен всех файлов (старых и новых).
Пакетная обработка. Здесь гораздо больше опций и возможностей. Для начала при помощи Ctrl выделяем изображения, которые необходимо подвергнуть обработке. В окошке «Пакетная обработка» можно добавить еще файлы или целые папки. В разделе «Выходные данные» нужно указать папку, в которую будут сохранены преобразованные изображения. Если вы хотите заменить исходные изображения преобразованными, то указывайте эту же папку. Ниже выбирайте формат преобразованных картинок. Здесь доступно порядка 20-30 разных форматов, но целесообразно выбирать JPEG.
Не забудьте открыть пункт «Опции». Эта кнопочка находится напротив пункта «Формат». В опциях следует переместить ползунок «Качество» во вкладке «Запись» в то положение, которое вам нужно. Если вы хотите сохранить исходное качество файлов, то перемещайте этот ползунок до упора вправо.
Теперь открываем вкладку «Преобразования» в окошке пакетной обработки. Здесь следует выбрать тип преобразования. Можно добавить на изображения водяной знак, обрезать их, изменить размер, добавить определенный тип фильтра, выполнить коррекцию. И все это сразу в пакетном режиме. Согласитесь, что очень удобно. Две самых часто используемых вебмастерами опции – это простановка водяного знака и изменение размера. Ниже кратко рассмотрим эти процессы.
1. Простановка водяного знака. Дважды кликните по пункту «Водяной знак», после чего откроется меню. Для начала нужно выбрать сам файл водяного знака и указать степень его прозрачности (тут все по вашему вкусу).
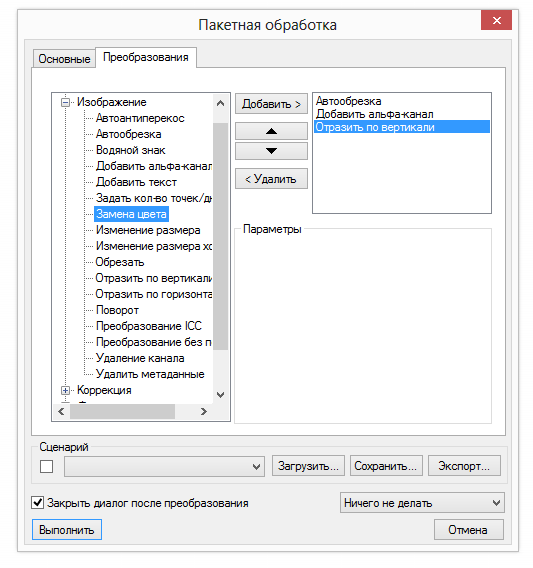
2. Изменение размера. Очень часто для поста нужно уменьшить большие изображения, сохранив их качество и пропорции. Для этого после выбора необходимых изображений и установки общих настроек дважды кликаем по пункту «Изменение размера» во вкладке «Преобразования». В параметрах указываем либо желаемую ширину, либо желаемую высоту. Второй параметр будет изменен автоматически (с сохранением пропорций). Но для этого должна быть поставлена галочка в пункте «Сохранять пропорции». При этом все файлы с меньшей шириной или высотой затрагиваться не будут (подгоняться под параметры будут лишь файлы, обладающие большей шириной или высотой). В конце также жмите «Выполнить».
На самом деле, возможностей у программы XnView масса.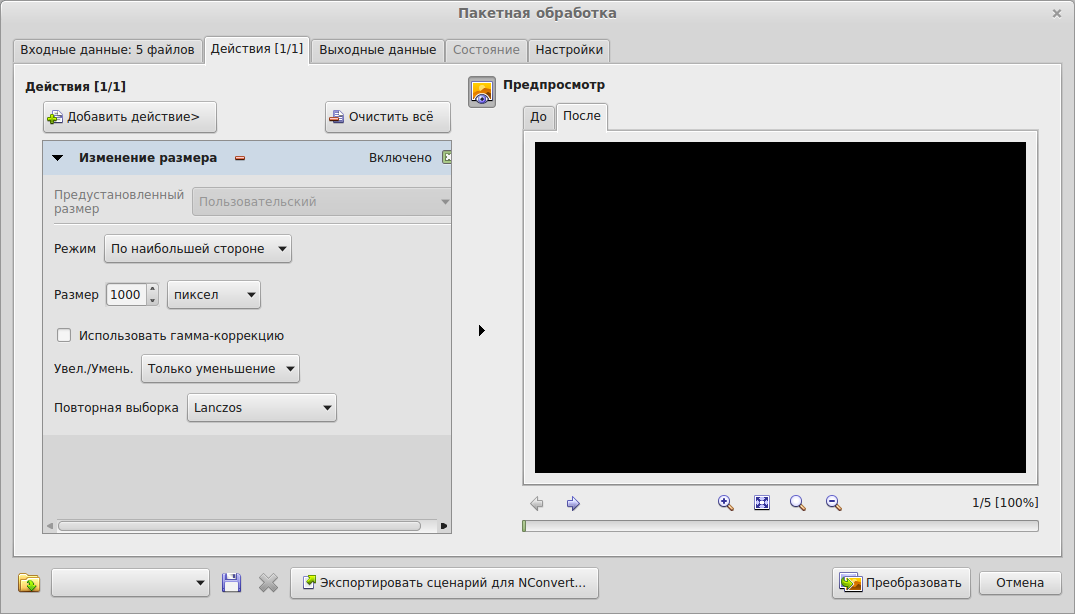 В данной статье мы рассмотрели лишь те из них, которые могут быть полезны с точки зрения пакетной обработки и конвертации графики
В данной статье мы рассмотрели лишь те из них, которые могут быть полезны с точки зрения пакетной обработки и конвертации графики
Удачи Вам в ваших начинаниях.
Интерфейс пакетной обработки
Введение
Все алгоритмы (включая модели), могут использоваться для пакетной обработки. Т.е. в этом случае они выполняются не один раз над одним набором данных, а несколько раз над разными наборами входных данных. Это полезно при обработке больших наборов данных, т.к. отпадает необходимость в многократном запуске алгоритма из панели инструментов.
Чтобы запустить алгоритм в режиме пакетной обработки выделите его в панели инструментов, вызовите контекстное меню и выберите пункт Execute as batch process.
Figure Processing 26:
Запуск пакетной обработки из констекстного меню
Таблица параметров
Запуск пакетной обработки во многом схож с выполнением единичной операции. Отличие лишь в том, что параметры теперь задаются для каждой итерации обработки. Диалог настройки в этом случае принимает вид таблицы.
Отличие лишь в том, что параметры теперь задаются для каждой итерации обработки. Диалог настройки в этом случае принимает вид таблицы.
Figure Processing 27:
Пакетная обработка
Каждая строка таблицы соответствует одному запуску алгоритма, в ячейках находятся параметры. Это похоже на обычный диалог настройки алгоритмов, только используется другое расположение элементов.
По умолчанию в таблице три строки, при необходимости добавить или удалить строки можно при помощи кнопок внизу окна.
После того, как размер таблицы (число строк в ней) задан, можно приступать к её заполнению.
Заполнение таблицы параметров
Большинство параметров задается либо вводом необходимого значения в поле, либо путем выбора значения из выпадающего списка.
Основное отличие в порядке заполнения параметров, соответствующих слоям или таблицам, а также выходным файлам. Необходимо помнить, что в случае пакетной обработки исходные слои (векторные или растровые) и таблицы загружаются из файлов на диске, а не берутся из открытых в QGIS. Поэтому пакетная обработка может быть запущена в любое время, даже при пустом проекте, когда обычный алгоритм не будет выполнен.
Поэтому пакетная обработка может быть запущена в любое время, даже при пустом проекте, когда обычный алгоритм не будет выполнен.
Указать имена исходных файлов можно как вводя путь к файлу в поле, так и воспользовавшись кнопкой возле соответствующего поля. В последнем случае откроется диалог выбора файлов с поддержкой множественного выбора. Если параметр является единичным файлом, то выбранные значения будут добавлены каждый в свою строку таблицы, при этом недостающие строки будут добавлены автоматически. Если же параметр принимает несколько величин, все выбранные файлы будут добавлены в одну строку c использованием точки с запятой (;) в качестве разделителя.
В отличие от обычного выполнения алгоритма, все результаты сохраняются в файлы, создание временных файлов не допускается. Указать имя выходного файла можно как вручную, так и воспользовавшись диалогом выбора.
После выбора выходного файла появится ещё один диалог, позволяющий автоматически заполнить остальные ячейки.
Figure Processing 28:
Диалог автозаполнения
Если выбрано значение Do not autofill (по умолчанию), в заданную ячейку будет просто вставлено выбранное имя файла. Если же выбрано любое другое значение, будут заполнены все ячейки. При этом имена файлов будут сформированы на основе указаного критерия автозаполнения. Такой подход значительно ускоряет заполнение таблицы параметров пакетной обработки.
Для автозаполнения могут использоваться как последовательные номера, так и значения других полей этой же строки. Это в частности позволяет задавать имена выходным файлам в зависимости от исходных данных.
Figure Processing 29:
Заполненые пути при пакетной обработке
Пакетная обработка фото в GIMP • Уроки GIMP для начинающих
Здравствуйте, уважаемые друзья! Во-первых, Поздравляю Вас с Днем Знаний! Качественных вам знаний в новом году. Во-вторых, сегодня для вас приготовил просто «вкусный» урок. Не побоюсь забежать вперед и сказать, что данный урок будет одним из популярных в будущем на моем блоге. Заинтригованы? Ну что же, поговорим мы сегодня про пакетную обработку фотографий с помощью редактора GIMP. Хорошее начало?
Не побоюсь забежать вперед и сказать, что данный урок будет одним из популярных в будущем на моем блоге. Заинтригованы? Ну что же, поговорим мы сегодня про пакетную обработку фотографий с помощью редактора GIMP. Хорошее начало?
Все мы знаем, что человек по своему существу ленивая особь. А лень, как известно, двигатель прогресса. Надоело ходить пешком, изобрел человек велосипед, машину, самолет и т.д.
А как быть с фотографиями? Представляете, и обработку фото тоже можно автоматизировать. Не зря люди придумали записывать повторяющиеся действия в специальные скрипты под названием экшены.
И пускай экшены существуют только для редактора фотошоп, в GIMP тоже полным полно своих скриптов и плагинов. Хотя если честно, встроенной функции записи своего экшена для редактора гимп не хватает.
Ну ладно! Отставим проблемы редактора в сторону и продолжим на позитивной ноте.
Что такое пакетная обработка? Это когда к 10, 100 и даже 1000 фотоснимкам применяется однажды записанный алгоритм обработки.
Представляете сколько у Вас ушло бы времени, если вам нужно было открыть файл, изменить его размер, увеличить резкость, поднять контрастность и сохранить в другом формате. Даже считать не буду.
Вот посидел человек, почесал свою репу и придумал плагин для автоматизации обработки фотографии.
Конечно же, вышеописанная мною последовательность это самый примитив, но порой вот как раз из-за таких действий и сжигается впустую много времени. Сделаю небольшое отступление от сегодняшней темы, раз заговорили про экономию своего времени, то рекомендую вам ознакомиться с этой и этой статьей.
Что же нам нужно, чтобы сэкономить время и обработать все фотографии пакетно? В первую очередь нам нужен графический редактор GIMP.
На все сто уверен, что у вас он уже есть. Далее нам нужно установить небольшое дополнение для пакетной обработки под названием BIMP.
Для этого переходите по следующей ссылке и на новой странице скачивайте установочный пакет, нажав по этой кнопке.
Пакетная обработка фото в GIMP
Сразу оговорюсь. Описанные мною действия применимы для системы Windows. Для операционных системы Linux процесс установки плагина отличается. Как разберусь сам, то обязательно дополню статью.
И так, плагин BIMP мы скачали, теперь двойным щелчком запустим его установку и проверим, чтобы он установился в туже директорию, где живет редактор GIMP.
Если все это мы сделали,то смело запускаем редактор и проверяем, появилась ли у нас заветная команда в меню «Фаил».
Если все ОК, тогда рассмотрим возможности плагина более подробно. К сожалению русской версии я пока не встречал, так что будем разбираться вместе, что и куда жать.
Редактор и плагин BIMP мы запустили, а что дальше?
Теперь нам нужно нажать на кнопку «Add images», чтобы выбрать исходную папку с фотографиями или одиночные файлы, которые мы хотим обработать пакетно.
854
В основном я использую команду «Add folders» (Добавить папку). А так выглядит окно с уже добавленными изображениями, которые пройдут пакетную обработку.
А так выглядит окно с уже добавленными изображениями, которые пройдут пакетную обработку.
После этого, нужно нажав на кнопку с плюсиком «Add», чтобы добавить команды, которые будут выполняться над фотографиями.
Какие команды можно применить «пакетно» к фотографиям?
Resize (Изменение размера). По умолчанию стоит процентное изменение по ширине и длине кадра.
Crop (Кадрирование). Кадрирование фото по заданным параметрам. Можно выбрать одну из встроенных команд из выпадающего меню или задать свои параметры в настройке «Manual crop». Также здесь задается начало кадрирования. По умолчанию стоит из центра. Учтите это.
Flip or Rotate (Зеркальное отражение и поворот). Пакетное изменение ориентации кадра. Также можно включить зеркальное отражение, как по горизонтали, так и по вертикали.
Color correction (Цветовая коррекция). Здесь вы можете задать нужный уровень Яркости и Контрастности на фото. Кроме этого, можно включить настройку «Convert to grayscale» и получить черно-белое изображение.
Sharp or Blur (Резкость или размытие). Все просто, смещая ползунок влево — добавляется резкость на фото, а вправо размытие.
Add a watermark (Добавить водяной знак). По умолчанию добавляет текстовый водяной знак с заданными параметрами (шрифт, размер и цвет). Также можно выбрать заранее сделанный водяной знак в фортмате картинки. Кроме этого имеется возможность регулировки прозрачности водяного знака и его положения на изображении.
Change format and compression (Изменить формат файла и велечину его сжатия). Данной командой вы можете выбрать формат конечного файла и задать уровень его сжатия (компреcсию). По умолчанию стоит JPEG c 85% качеством.
По умолчанию стоит JPEG c 85% качеством.
Rename with a pattern (Переименовать по заданной маске). Ну и как без этого. Данной командой вы можете задать имя конечного файла по маске. По умолчанию сохраняется исходное имя файла картинки.
Other GIMP procedure (Выполнить другую команду из встроенных в редактор GIMP). Как вы уже догадались, здесь можно задать любую другую команду из встроенных в редактор GIMP. Как говорит Шпуля из мультика «Фиксики» — «Прелесть!». Не так ли?
После того, как вы задали команды, нужно выбрать конечную папку, куда будут помещены обработанные фотографии.Для этого нужно нажать сюда. По умолчанию, это папка с вашими документами.
Сделали? Тогда запускаем процесс пакетной обработки, нажав на кнопку «Apply».
Спустя некоторое время (зависит от количества фотографий и от выбранных вами команд), плагин остановится и появится надпись об успешной работе. После этого жмем на кнопку «Close», чтобы закрыть плагин BIMP.
После этого жмем на кнопку «Close», чтобы закрыть плагин BIMP.
Ура! Вот и все. Мы буквально за несколько минут смогли пакетно обработать значительное количество фотографий. Здорово! Не так ли?
Но возможности плагина BIMP на сегодня не заканчиваются, более подробно про еще одну «тайную» возможность данного плагина я расскажу в одном из ближайших уроков. А сейчас чуть-чуть заикнусь.
Слышали про такую социальную сеть Инстаграм? А знаете, что фотографии для нее строго квадратного формата и загружаться могут только с телефона. Так вот, есть специальная программка, которая позволяет загружать фотографии в Инстаграм с компьютера. А вот с помощью плагина BIMP можно подготовить 10, 100 и даже 1000 фотографий для Инстаграма.
Но об этом, в другой серии.
С уважением, Антон Лапшин!
Пакетная обработка файлов в Corel PaintShop Photo Pro
Пакетная обработка файлов в Corel PaintShop Photo Pro
С помощью функции пакетной обработки можно обработать несколько файлов. В программе «PaintShop Photo Pro» можно создавать копии исходных файлов, преобразовывать их, а затем сохранять копии в выбранной папке для вывода. Рассмотрим применение пакетной обработки на примере преобразования нескольких файлов в новый формат. Для этого выберите на вкладке «Файл» команду «Пакетная обработка».
В программе «PaintShop Photo Pro» можно создавать копии исходных файлов, преобразовывать их, а затем сохранять копии в выбранной папке для вывода. Рассмотрим применение пакетной обработки на примере преобразования нескольких файлов в новый формат. Для этого выберите на вкладке «Файл» команду «Пакетная обработка».
В открывшемся диалоговом окне нажмите кнопку «Обзор», а затем выберите файлы, которые требуется обработать в диалоговом окне выбора файлов. В окне группы «Режим сохранения» необходимо выбрать один из предложенных параметров. Рассмотрим эти параметры более подробно. Параметр «Создать тип» выбирается чаще всего, и для него требуется только установить новый тип вывода в поле «Тип» окна группы «Параметры сохранения». Можно также указать, чтобы макрос запускался с этим параметром.
При выборе параметра «Копировать» требуется, чтобы в окне группы «Макрос» был определен макрос. Результатом применения данного параметра становится считывание файла и запуск макроса, затем файл сохраняется в новое местоположение с новым именем.
При использовании параметра «Перезаписать» файл считывается, для него запускается макрос, затем файл сохраняется в исходное местоположение.
И, наконец, при выборе параметра «Сохранить макрос» требуется, чтобы в окне группы «Макрос» был определен макрос. При выборе этого параметра файл считывается, для него запускается макрос. Стоит отметить, что поскольку сохранение при данном выборе параметра не выполняется, этот параметр следует использовать, только если известно, что операция сохранения предусмотрена макросом.
Выберите параметр «Создать тип».
Нажмите кнопку «Параметры», чтобы открыть диалоговое окно «Параметры сохранения». Стоит отметить, что если параметры для выбранного формата файла отсутствуют, то кнопка «Параметры» будет недоступной.
Выберите необходимый коэффициент сжатия и нажмите «Ок», однако стоит учесть, чем больше коэффициент сжатия, тем ниже качество изображения.
Нажмите кнопку обзор и в появившемся диалоговом окне выберите путь для сохранения файлов. После применения всех необходимых настроек, нажмите кнопку «Начать». Файлы обработаются и сохранятся в заданном месте.
После применения всех необходимых настроек, нажмите кнопку «Начать». Файлы обработаются и сохранятся в заданном месте.
Adobe Lightroom. Отбор и пакетная обработка
Всем знакома ситуация, когда количество фотографий из каждой поездки исчисляется тысячами, на жёстком диске пылятся гигабайты прошлогодних съёмок, друзья и коллеги уже перестали спрашивать “когда будут фото из отпуска?”, а терпения и времени, чтобы разобрать и, тем более, обработать этот снежный ком не хватает.
Новых интересных съёмок — всё больше, старые съёмки кажутся уже не такими любопытными, но ни те, ни другие не увидят и не оценят, пока автор не освоит систему взаимодействия с собственным архивом.
На практическом трёхчасовом семинаре Анна Арчен расскажет о том, как ускорить процесс отбора и обработки, используя возможности Adobe Lightroom.
- как лучше организовать личный фотоархив
- как быстро сортировать и отбирать фотографии в Adobe Lightroom
- чем руководствоваться при отборе
- как составить несколько серий из одной съёмки
- как составить одну серию из разных съёмок
- как быстро обработать большое количество фотографий из поездок или семейного архива, создать из них серии для публикаций в соцсетях, для печати альбома или небольшого авторского проекта.

Всегда наступает критический момент, когда нужно сделать прорыв и потратить время и усилия на то, чтобы стать “быстрее, выше, сильнее”. Я, как сейчас, помню то самое ощущение “эврика”, которое испытала однажды вечером, когда самостоятельно разобралась с тем, как грамотно сортировать фотографии в лайтруме.
Это элементарные инструменты и совершенно очевидная логика, однако их применение навсегда изменило мою работу к лучшему. В тот вечер я на одном дыхании разобрала три съёмки.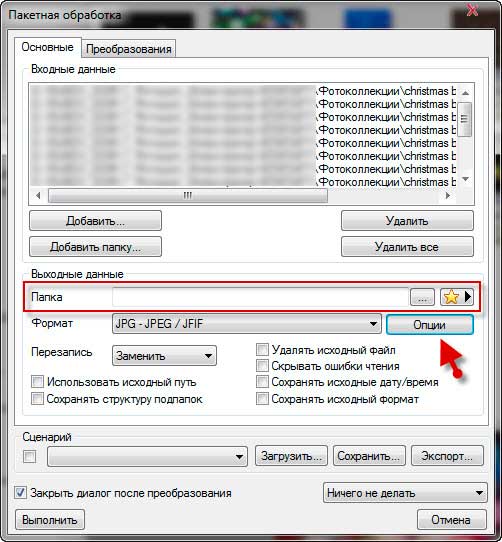 И в настоящий момент сортировка каждого проекта занимает у меня не более нескольких приятных часов. Никакого откладывания “на потом”, никаких завалов и связанных с этим моральных пыток.”
И в настоящий момент сортировка каждого проекта занимает у меня не более нескольких приятных часов. Никакого откладывания “на потом”, никаких завалов и связанных с этим моральных пыток.”
Отзывы о курсе
Обработка «Пакетная обработка претензий»
Обработка находится в подсистеме «Дополнительные возможности» меню «Сервис». Предназначена для перевода претензий в очередное состояние.
На первой закладке выбирается один из вариантов отбора претензий.
- «Вариант отбора претензий» – может принимать следующие значения:
- «Все» – для обработки будут выбраны все имеющиеся претензии;
- «В указанном состоянии» – для обработки будут выбраны претензии, находящиеся в состоянии, указанном в реквизите «Состояние»;
- «Выбрать вручную» – необходимо выбрать вручную те претензии, которые будут обрабатываться.
После нажатия на кнопку «Далее» на очередной закладке появится список отобранных претензий, его можно отредактировать (добавить/удалить претензии).
На следующей закладке необходимо выбрать действие и дату смены состояния (произвольную или рабочую).
- «Тип действия над претензиями» – может принимать следующие значения:
- «Смена состояний по условиям» – при нажатии на кнопку «Далее», происходит обработка претензий и на следующей закладке появляются те претензии, для которых возможна автоматическая смена состояния, т.е. сработали условия перехода из текущего состояния в следующее. Далее при помощи галочек необходимо выбрать нужные претензии и нажать на кнопку «Выполнить», при этом происходит пакетная обработка по переводу в новое состояние;
- «Смена состояний вручную» – пункт появляется только в том случае, если все претензии с предыдущей закладки находятся в одинаковом состоянии, при нажатии на кнопку «Далее» на следующей закладке выводится список возможных переходов из текущего состояния. Далее при помощи галочек необходимо выбрать нужные претензии и нажать на кнопку «Выполнить», при этом происходит пакетная обработка по переводу в новое состояние;
- «Печать документов» – при нажатии на кнопку «Далее» на следующей закладке выводится список названий возможных печатных форм. Далее при помощи галочек необходимо выбрать нужные формы и нажать «Выполнить». Происходит формирование указанных печатных форм для всех выбранных ранее документов.
 Далее при помощи галочек необходимо выбрать нужные формы и нажать «Выполнить». Происходит формирование указанных печатных форм для всех выбранных ранее документов.
Далее при помощи галочек необходимо выбрать нужные формы и нажать «Выполнить». Происходит формирование указанных печатных форм для всех выбранных ранее документов.На следующей закладке необходимо отметить галочками претензии, состояния которых будут изменены:
Пакетный процесс — обзор
1 ВВЕДЕНИЕ
Периодический процесс широко используется в химической, биохимической, фармацевтической и сельскохозяйственной промышленности. Их гибкость в производстве дорогостоящих продуктов во время коротких производственных кампаний объясняет их широкое использование. При высокой степени автоматизации управление серийным процессом является довольно сложной задачей. Это объясняется сочетанием их конечной продолжительности, нелинейного поведения, их естественных нестационарных и многокритериальных критериев.Некоторые методы и инструменты для мониторинга пакетного процесса были разработаны за последнее десятилетие. Для пакетных процессов эти инструменты включают многофакторный анализ главных компонентов (MPCA) и многофакторный частичный метод наименьших квадратов (MPLS) (П.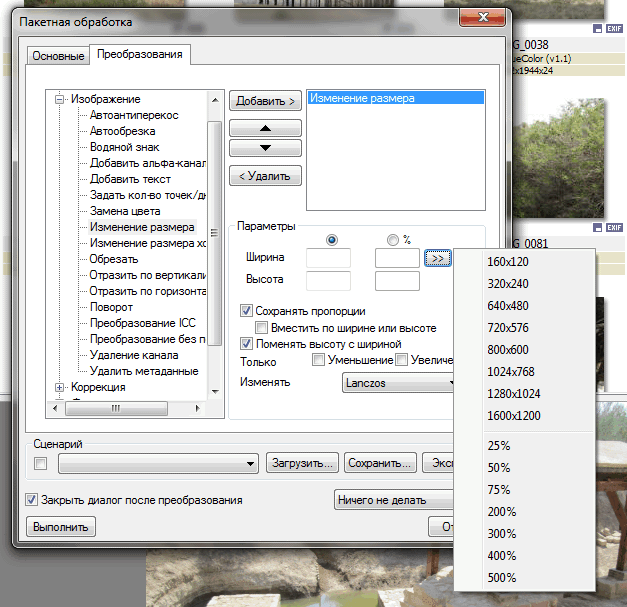 Номикос и Дж. Ф. МакГррегор, 1994; Т. Курти, Дж. Ли и Дж. Ф. МакГрегор, 1995). . Они извлекают основную информацию из данных с помощью многомерного статистического анализа. В этой статье MPCA будет применяться для мониторинга и диагностики сбоев в пакетном процессе. По сути, этот метод строит статистическую модель MPCA в соответствии с нормальными переменными процесса вокруг их средних траекторий.Затем он сравнивает отклонение новой партии от средней траектории с моделью MPCA. Любое отклонение от модели, которое нельзя статистически отнести к обычным вариациям процесса, указывает на то, что новая партия имеет низкое качество.
Номикос и Дж. Ф. МакГррегор, 1994; Т. Курти, Дж. Ли и Дж. Ф. МакГрегор, 1995). . Они извлекают основную информацию из данных с помощью многомерного статистического анализа. В этой статье MPCA будет применяться для мониторинга и диагностики сбоев в пакетном процессе. По сути, этот метод строит статистическую модель MPCA в соответствии с нормальными переменными процесса вокруг их средних траекторий.Затем он сравнивает отклонение новой партии от средней траектории с моделью MPCA. Любое отклонение от модели, которое нельзя статистически отнести к обычным вариациям процесса, указывает на то, что новая партия имеет низкое качество.
Метод MPCA основан на предположении, что все траектории данных в пакетном процессе согласованы. Статистическая модель построена с использованием этих данных равной продолжительности. Но многие ситуации разные. Общая продолжительность пакетов и продолжительность различных этапов внутри пакетов не совпадают.Обычно изменение от партии к партии может влиять на статистическую модель, даже на диагностику неисправностей.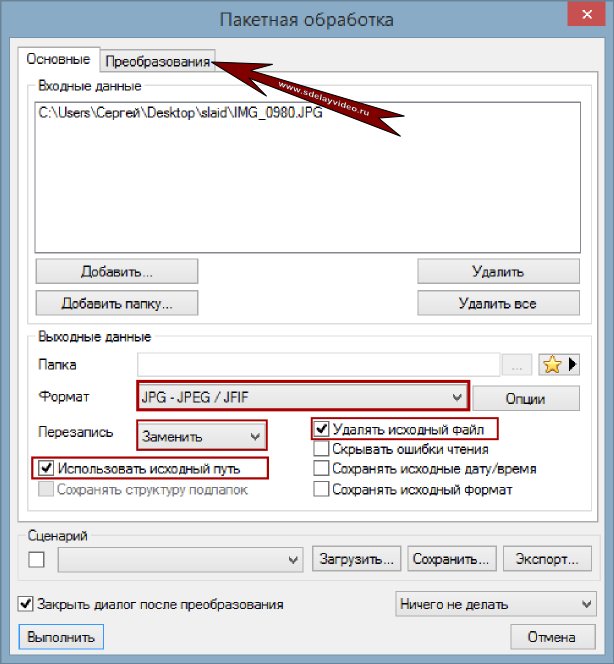 Таким образом, одна важная работа — сделать все данные процесса согласованными.
Таким образом, одна важная работа — сделать все данные процесса согласованными.
При распознавании речи несинхронизированные режимы — обычная проблема. Одно и то же слово может произноситься с разной продолжительностью и интенсивностью в разных ситуациях и разными говорящими; Система распознавания речи должна уметь их классифицировать. Этот процесс завершается извлечением признаков из речевых сигналов. Динамическое преобразование времени (DTW) — это метод гибкой схемы сопоставления с образцом.Он переводит, сжимает и расширяет пары шаблонов так, чтобы схожие черты в этих двух шаблонах совпадали (К. Майерс, Л. Р. Рабинер и А. Э. Розенберг, 1980; Х. Ф. Сильверман и Д. П. Морган, 1990). DTW широко используется в распознавании устных слов. Точно так же DTW имеет возможность синхронизировать две траектории из пакетного процесса и обеспечивает элегантное решение проблемы синхронизации пакетных траекторий.
В этом документе предлагается метод CMPCA для мониторинга и диагностики неисправностей в пакетном процессе. Это основано на комбинации MPCA и DTW. DTW может синхронизировать все данные из пакетного процесса. Для построения модели MPCA в первую очередь должны быть согласованы обычные исторические данные. Затем можно построить модель CMPCA, которая не только сохраняет информацию о данных, но и избегает остатков модели. Более того, новые данные партии также удаляются с помощью DTW, а затем проецируются на модель CMPCA для диагностики неисправностей.
Это основано на комбинации MPCA и DTW. DTW может синхронизировать все данные из пакетного процесса. Для построения модели MPCA в первую очередь должны быть согласованы обычные исторические данные. Затем можно построить модель CMPCA, которая не только сохраняет информацию о данных, но и избегает остатков модели. Более того, новые данные партии также удаляются с помощью DTW, а затем проецируются на модель CMPCA для диагностики неисправностей.
Данная статья организована следующим образом. Сначала дается краткий обзор стандартной процедуры MPCA, а затем вводится анализ DTW.Методология CMPCA с использованием DTW подробно разработана и будет использоваться для диагностики неисправностей в пакетных процессах на примерах последовательности. Наконец, выводы и обсуждения приведены в последнем разделе.
Пакетная обработка | Документация MuleSoft
В основе пакетной обработки Mule лежит пакетная работа. Пакетное задание — это область, которая разбивает большие сообщения на записи, которые Mule обрабатывает асинхронно. Точно так же потоки обрабатывают сообщения, пакетные задания обрабатывают записи.
Точно так же потоки обрабатывают сообщения, пакетные задания обрабатывают записи.
Пакетная структура XML была изменена в Mule 4.0. В приведенном ниже примере показаны сокращенные сведения для выделения элементов пакета.
<пакет: записи-процесса>
<обработчик событий />
<обработчик событий />
<обработчик событий />
<обработчик событий />
Пакетное задание содержит один или несколько этапов пакетного задания, которые воздействуют на записи при их перемещении по пакетному заданию.
Каждый шаг пакетного задания содержит процессоры, которые воздействуют на запись для преобразования, маршрутизации, обогащения или иной обработки содержащихся в ней данных. Используя функциональность существующих процессоров Mule, пакетный шаг предлагает большую гибкость в отношении того, как пакетное задание обрабатывает записи. Дополнительные сведения см. В разделе «Уточнение обработки шагов пакета».
Используя функциональность существующих процессоров Mule, пакетный шаг предлагает большую гибкость в отношении того, как пакетное задание обрабатывает записи. Дополнительные сведения см. В разделе «Уточнение обработки шагов пакета».
Пакетное задание выполняется, когда поток достигает раздела записей процесса пакетного задания. При запуске Mule создает новый экземпляр пакетного задания.Когда экземпляр задания становится исполняемым, пакетный движок отправляет задачу для каждого блока записи в Пул ввода-вывода для обработки каждой записи. Параллелизм происходит автоматически при записи блочный уровень. Среда выполнения Mule использует свои возможности автонастройки, чтобы определить, сколько потоков использовать и какой уровень параллелизма применять (см. Механизм выполнения).
Когда начинается выполнение пакетного задания, Mule разбивает входящее сообщение на записи, сохраняет их в постоянной очереди, а также запрашивает и планирует эти записи в блоках записей для обработки. По умолчанию среда выполнения хранит 100 записей на каждом шаге пакета. Вы можете настроить этот размер в соответствии с требуемой производительностью. Дополнительные сведения см. В разделе «Уточнение обработки шагов пакета».
По умолчанию среда выполнения хранит 100 записей на каждом шаге пакета. Вы можете настроить этот размер в соответствии с требуемой производительностью. Дополнительные сведения см. В разделе «Уточнение обработки шагов пакета».
После того, как все записи прошли все этапы пакетной обработки, среда выполнения завершает выполнение экземпляра пакетного задания и сообщает результат пакетного задания, указывая, какие записи выполнены успешно, а какие не удалось выполнить.
Обработка ошибок
Пакетные задания могут обрабатывать любой сбой на уровне записи, который может произойти при обработке, чтобы предотвратить сбой всего пакетного задания.Кроме того, вы можете устанавливать или удалять переменные в отдельных записях, чтобы во время пакетной обработки Mule мог маршрутизировать или иным образом воздействовать на записи в пакетном задании в соответствии с переменной (назначенной выше). Дополнительные сведения см. В разделе «Обработка ошибок во время пакетного задания».
Пакетное задание против экземпляра пакетного задания
Хотя они определены в контексте выше, стоит уточнить термины пакетное задание и экземпляр пакетного задания, поскольку они связаны друг с другом.
Пакетное задание — это элемент области действия в приложении, в котором Mule обрабатывает полезные данные сообщения как пакет записей.Термин пакетное задание включает все три фазы обработки: загрузка и отправка, обработка и завершение.
Экземпляр пакетного задания возникает в приложении Mule всякий раз, когда поток Mule выполняет пакетное задание. Mule создает экземпляр пакетного задания на этапе загрузки и отправки. Каждый экземпляр пакетного задания идентифицируется внутри с помощью уникальной строки, известной как идентификатор экземпляра пакетного задания .
Этот идентификатор полезен, если вы хотите, например, передать идентификатор локального экземпляра задания во внешнюю систему для ссылки и управления данными, улучшить настраиваемое ведение журнала задания или даже отправить уведомление по электронной почте или SMS для значимых событий, связанных с этим конкретным пакетом. экземпляр работы.См. Идентификатор экземпляра пакетного задания, чтобы узнать больше об этом идентификаторе и о том, как его настроить.
экземпляр работы.См. Идентификатор экземпляра пакетного задания, чтобы узнать больше об этом идентификаторе и о том, как его настроить.
Выбор технологии пакетной обработки — Центр архитектуры Azure
- 3 минуты на чтение
В этой статье
Решениядля больших данных часто используют длительные пакетные задания для фильтрации, агрегирования или иной подготовки данных для анализа.Обычно эти задания включают чтение исходных файлов из масштабируемого хранилища (например, HDFS, Azure Data Lake Store и хранилище Azure), их обработку и запись вывода в новые файлы в масштабируемом хранилище.
Ключевым требованием таких механизмов пакетной обработки является возможность масштабирования вычислений для обработки большого объема данных. Однако в отличие от обработки в реальном времени ожидается, что пакетная обработка будет иметь задержки (время между приемом данных и вычислением результата), которые измеряются от нескольких минут до часов.
Однако в отличие от обработки в реальном времени ожидается, что пакетная обработка будет иметь задержки (время между приемом данных и вычислением результата), которые измеряются от нескольких минут до часов.
Выбор технологий для пакетной обработки
Аналитика Azure Synapse
Azure Synapse — это распределенная система, предназначенная для анализа больших данных. Он поддерживает массовую параллельную обработку (MPP), что делает его подходящим для выполнения высокопроизводительной аналитики. Рассмотрим Azure Synapse, если у вас большие объемы данных (более 1 ТБ) и вы выполняете аналитическую рабочую нагрузку, которая выиграет от параллелизма.
Аналитика озера данных Azure
Data Lake Analytics — это служба аналитики по запросу.Он оптимизирован для распределенной обработки очень больших наборов данных, хранящихся в Azure Data Lake Store.
- Языки: U-SQL (включая расширения Python, R и C #).
- интегрируется с Azure Data Lake Store, большими двоичными объектами службы хранилища Azure, базой данных SQL Azure и Azure Synapse.
- Модель ценообразования указана за работу.
HDInsight
HDInsight — это управляемая служба Hadoop. Используйте его для развертывания кластеров Hadoop и управления ими в Azure. Для пакетной обработки вы можете использовать Spark, Hive, Hive LLAP, MapReduce.
- Языки: R, Python, Java, Scala, SQL
- Аутентификация Kerberos с Active Directory, контроль доступа на основе Apache Ranger
- Предоставляет вам полный контроль над кластером Hadoop
Azure Databricks
Azure Databricks — это аналитическая платформа на основе Apache Spark. Вы можете думать об этом как о «Искре как услуге». Это самый простой способ использовать Spark на платформе Azure.
- Языки: R, Python, Java, Scala, Spark SQL
- Быстрый запуск кластера, автоматическое завершение, автомасштабирование.
- Управляет кластером Spark за вас.
- Встроенная интеграция с хранилищем BLOB-объектов Azure, хранилищем озера данных Azure (ADLS), Azure Synapse и другими службами. См. Источники данных.
- Аутентификация пользователя с помощью Azure Active Directory.
- Сетевые записные книжки для совместной работы и исследования данных.
- Поддерживает кластеры с поддержкой графического процессора
 См. Источники данных.
См. Источники данных.Набор средств разработки распределенных данных Azure
Набор средств разработки распределенных данных (AZTK) — это инструмент для подготовки Spark по требованию в кластерах Docker в Azure.
AZTK не является службой Azure. Скорее, это клиентский инструмент с интерфейсом командной строки и Python SDK, созданный на основе пакетной службы Azure. Этот вариант дает вам максимальный контроль над инфраструктурой при развертывании кластера Spark.
- Принесите свой собственный образ Docker.
- Используйте низкоприоритетные виртуальные машины со скидкой 80%.
- Кластеры смешанного режима, использующие как низкоприоритетные, так и выделенные виртуальные машины.
- Встроенная поддержка хранилища BLOB-объектов Azure и подключения к Azure Data Lake.

Ключевые критерии выбора
Чтобы сузить круг выбора, сначала ответьте на следующие вопросы:
Вам нужна управляемая служба, а не управление собственными серверами?
Вы хотите создать логику пакетной обработки декларативно или императивно?
Будете ли вы выполнять пакетную обработку пакетами? Если да, рассмотрите варианты, которые позволяют автоматически завершить кластер или чья модель ценообразования рассчитана на пакетное задание.
Вам нужно запрашивать реляционные хранилища данных вместе с пакетной обработкой, например, для поиска справочных данных? Если да, рассмотрите варианты, которые позволяют запрашивать внешние реляционные хранилища.
Матрица возможностей
В следующих таблицах приведены основные различия в возможностях.
Общие возможности
| Возможность | Аналитика озера данных Azure | Лазурный синапс | HDInsight | Azure Databricks |
|---|---|---|---|---|
| Управляемая служба | Есть | Есть | Есть 1 | Есть |
| Реляционное хранилище данных | Есть | Есть | № | № |
| Ценовая модель | За пакетное задание | По часам кластера | По часам кластера | Блок данных 2 + час кластера |
[1] С ручной настройкой.
[2] Блок Databricks (DBU) — это единица производительности обработки в час.
Возможности
| Возможность | Аналитика озера данных Azure | Лазурный синапс | HDInsight с Spark | HDInsight с Hive | HDInsight с Hive LLAP | Azure Databricks |
|---|---|---|---|---|---|---|
| Автомасштабирование | № | № | Есть | Есть | Есть | Есть |
| Уровень детализации | На одно задание | На кластер | На кластер | На кластер | На кластер | На кластер |
| Кэширование данных в памяти | № | Есть | Есть | № | Есть | Есть |
| Запрос из внешних реляционных хранилищ | Есть | № | Есть | № | № | Есть |
| Аутентификация | Azure AD | SQL / Azure AD | № | Azure AD 1 | Azure AD 1 | Azure AD |
| Аудит | Есть | Есть | № | Есть 1 | Есть 1 | Есть |
| Безопасность на уровне строк | № | Есть 2 | № | Есть 1 | Есть 1 | № |
| Поддерживает брандмауэры | Есть | Есть | Есть | Есть 3 | Есть 3 | № |
| Динамическое маскирование данных | № | Есть | № | Есть 1 | Есть 1 | № |
[1] Требуется использование присоединенного к домену кластера HDInsight.
[2] Только предикаты фильтра. См. Раздел Безопасность на уровне строк
[3] Поддерживается при использовании в виртуальной сети Azure.
Пакетная обработка Инструмент Batch Processing позволяет выполнять повторный анализ нескольких наборов данных с использованием существующего шаблона анализа и при необходимости выводить проанализированные результаты в шаблон Word для отчетности.Вы можете обрабатывать несколько файлов данных с диска или перебирать данные, уже находящиеся в вашем проекте. Чтобы создать шаблон анализа, выполните операцию (например, подгонку кривой) и установите для параметра Пересчет значение Авто или Вручную. При желании вы можете добавить лист результатов, который содержит связанные со вставкой результаты (например, имя файла или подмножество значений из таблицы параметров, созданной при подборе кривой) из операции анализа. При желании вы можете выбрать вывод проанализированных результатов непосредственно в файл Word / PDF, используя закладки в шаблоне Word. Закладки в шаблоне Word можно использовать только при добавлении в указанный шаблон анализа с помощью диалогового окна «Добавить закладки Word в шаблон анализа». Дополнительный рабочий лист Закладки будет автоматически создан для хранения закладок, результатов анализа, связанных с ячейками из отчета анализа, и размеров экспортируемых графиков. Когда инструмент используется для обработки нескольких файлов на диске, параметры импорта (например,g., пользовательские настройки ASCII или настройки фильтра из мастера импорта) могут быть сохранены как часть шаблона анализа . Переменные, извлеченные во время импорта, могут быть вставлены в таблицу результатов , и эта информация затем появится в сводном отчете , созданном с помощью инструмента пакетной обработки. Шаблон анализа может включать:
После завершения всех необходимых настроек в диалоговом окне Batch Processing и нажатия OK , все настройки, кроме Batch Processing Mode и содержимое в Список файлов , будут сохранены в шаблоне анализа для дальнейшего использования.
Диалоговое окно пакетной обработкиЧтобы открыть, щелкните Файл , а затем щелкните Пакетная обработка .
ПримерыПример 1: Импорт.DAT и выполнить аппроксимацию нелинейной кривойВ этом примере мы импортируем три файла .dat и выполним аппроксимацию нелинейной кривой.
Пример 2. Выполнение пакетного анализа групп файлов CSVВ этом руководстве показано, как выполнять пакетный анализ сгруппированных наборов данных с использованием шаблона анализа с несколькими таблицами данных. Пример 3. Выполнение пакетного анализа и создание отчетов с использованием настраиваемого шаблона MS WordВ этом руководстве показано, как выполнять пакетный анализ с помощью шаблона Word для отчетов. Пример 4: Выполните пакетную обработку листов в файле проекта Если вы уже импортировали исходные данные в несколько листов в проекте или хотите выполнить пакетную обработку на нескольких листах, которые являются промежуточными результатами предварительной обработки, используется Источник данных = Использовать существующие рабочие листы . В этом примере мы используем файл Excel HouseholdCareSamples.xls в папке <Папка установки Origin> \ Origin2018 \ Samples \ Statistics \ . Файл Excel содержит несколько рабочих листов, в каждом из которых есть запасы чистящих средств супермаркета. Мы собираемся рассчитать запасы разных видов на каждом рынке и суммировать их в таблице результатов. Сначала нам нужно подготовить шаблон анализа
Затем мы можем импортировать весь файл Excel и выполнить пакетную обработку.
Пример 5. Выполнение пакетной обработки наборов данных, сгруппированных по столбцурабочего листа.Выберите справку : Origin Central — вкладка Образцы анализа , установите для образцов в пакетную обработку, а затем щелкните Столбцы групповой обработки пакетной обработки , чтобы увидеть пример того, как использовать несколько диапазонов с информацией о группировке в качестве входных данных для выполнения статистика партии. |
 Затем вы можете использовать инструмент пакетной обработки для создания сводного отчета, компилирующего данные таблицы результатов из нескольких файлов или наборов данных.
Затем вы можете использовать инструмент пакетной обработки для создания сводного отчета, компилирующего данные таблицы результатов из нескольких файлов или наборов данных.
 Для Batch Processing Mode установлено значение Repeated Import into Active Window , шаблон анализа будет сохранен в UFF по умолчанию. Для Batch Processing Mode установлено значение Load Analysis Template , он обновит исходный шаблон (в этом случае шаблон анализа не должен находиться в папке установки Origin или подпапке, иначе он будет сохранен в UFF).
Для Batch Processing Mode установлено значение Repeated Import into Active Window , шаблон анализа будет сохранен в UFF по умолчанию. Для Batch Processing Mode установлено значение Load Analysis Template , он обновит исходный шаблон (в этом случае шаблон анализа не должен находиться в папке установки Origin или подпапке, иначе он будет сохранен в UFF). Вы можете установить @BST, выбрав Инструменты: Системные переменные .
Вы можете установить @BST, выбрав Инструменты: Системные переменные .  Используйте это, чтобы указать шаблон анализа для пакетной обработки.
Используйте это, чтобы указать шаблон анализа для пакетной обработки. Используйте этот параметр, чтобы указать, куда экспортировать результаты пакетного анализа, используя закладки в шаблоне Word. Обратите внимание, что файлы Word и PDF будут экспортированы в одно и то же место.
Используйте этот параметр, чтобы указать, куда экспортировать результаты пакетного анализа, используя закладки в шаблоне Word. Обратите внимание, что файлы Word и PDF будут экспортированы в одно и то же место.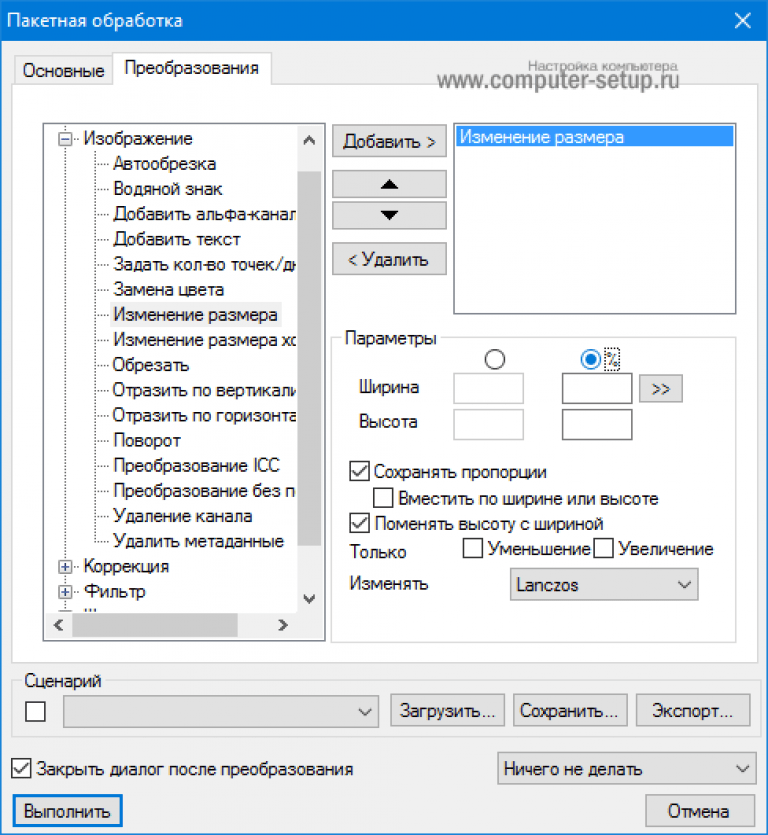
 Поскольку матрицы могут хранить данные или изображения, вы можете импортировать файлы данных (* .dat, * .txt и т. Д.) В матрицу, которая настроена на отображение в режиме данных или режиме изображения; или вы можете импортировать файлы изображений (*.jpg, * .tif и т. д.). Вы можете импортировать файлы в матрицы в любом из режимов пакетной обработки .
Поскольку матрицы могут хранить данные или изображения, вы можете импортировать файлы данных (* .dat, * .txt и т. Д.) В матрицу, которая настроена на отображение в режиме данных или режиме изображения; или вы можете импортировать файлы изображений (*.jpg, * .tif и т. д.). Вы можете импортировать файлы в матрицы в любом из режимов пакетной обработки . Использовать существующие рабочие листы . Щелкните стрелку, указывающую вправо, чтобы отфильтровать по листов в книге , листов в папке , листов в папке (рекурсивно) или листов в проекте . Кроме того, вы можете выбрать «Выбрать рабочие листы», чтобы открыть Sheet Browser . Сброс очищает окно выбора.
Использовать существующие рабочие листы . Щелкните стрелку, указывающую вправо, чтобы отфильтровать по листов в книге , листов в папке , листов в папке (рекурсивно) или листов в проекте . Кроме того, вы можете выбрать «Выбрать рабочие листы», чтобы открыть Sheet Browser . Сброс очищает окно выбора. .. and Source = Import from Files ).
.. and Source = Import from Files ). Дополнительные сведения см. В разделах «Сохранение настроек ASCII» и «Сохранение фильтров».
Дополнительные сведения см. В разделах «Сохранение настроек ASCII» и «Сохранение фильтров».

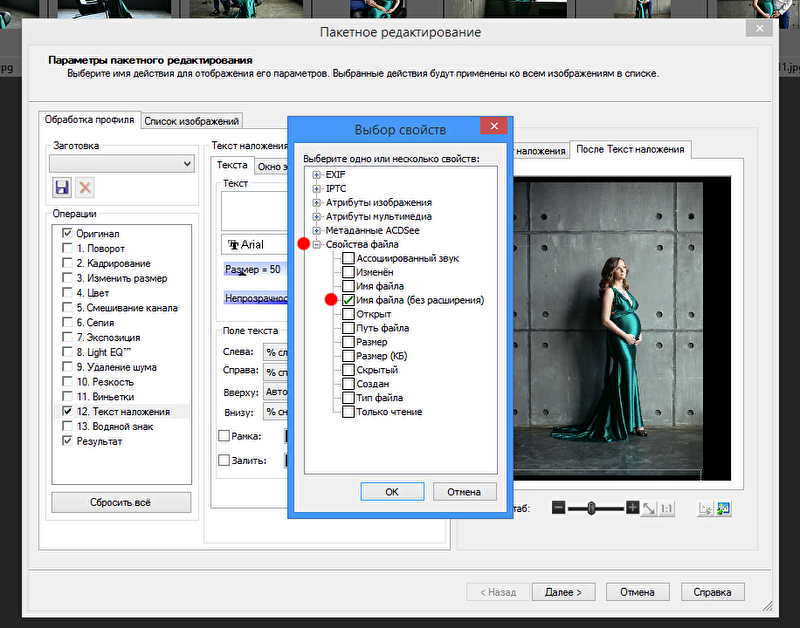 Он используется, чтобы указать, нужно ли добавлять строки меток к ячейкам столбца под строками меток столбца.
Он используется, чтобы указать, нужно ли добавлять строки меток к ячейкам столбца под строками меток столбца. Обратите внимание:
Обратите внимание: ogw .
ogw . В следующем примере показано, как выполнять пакетную обработку на нескольких листах.
В следующем примере показано, как выполнять пакетную обработку на нескольких листах. Установите Количество Lindes подзаголовков на 1 и Длинные имена на 1, чтобы установить первую строку как Длинное имя,
Установите Количество Lindes подзаголовков на 1 и Длинные имена на 1, чтобы установить первую строку как Длинное имя, ogwu .
ogwu .
Микропакетная обработка против потоковой обработки
Микропакетная обработка — это практика сбора данных небольшими группами («пакетами») с целью принятия мер (обработки) этих данных. Сравните это с традиционной «пакетной обработкой», которая часто подразумевает выполнение действий с большой группой данных. Микропакетная обработка — это вариант традиционной пакетной обработки, в котором обработка данных происходит чаще, так что обрабатываются меньшие группы новых данных. Как при микропакетной обработке, так и при традиционной пакетной обработке данные собираются на основе заранее определенного порога или частоты до того, как произойдет какая-либо обработка.
Сравните это с традиционной «пакетной обработкой», которая часто подразумевает выполнение действий с большой группой данных. Микропакетная обработка — это вариант традиционной пакетной обработки, в котором обработка данных происходит чаще, так что обрабатываются меньшие группы новых данных. Как при микропакетной обработке, так и при традиционной пакетной обработке данные собираются на основе заранее определенного порога или частоты до того, как произойдет какая-либо обработка.
микропакетной обработки В традиционном мире данных рабочие нагрузки были преимущественно ориентированы на пакетную обработку.То есть мы собирали данные в группы, затем очищали и преобразовывали данные перед загрузкой в репозиторий, например хранилище данных, для подачи стандартных отчетов на ежедневной, еженедельной, ежемесячной, ежеквартальной и годовой основе. Этого цикла было достаточно, когда большинство компаний преимущественно взаимодействовали с клиентами в физическом мире.
По мере того, как мир становится все более цифровым и «постоянно активным», а наши взаимодействия постоянно генерируют огромные объемы данных, предприятия внедряют новые технологические подходы для создания и поддержания конкурентного преимущества за счет более немедленного и персонализированного взаимодействия. Это были микропакетная обработка, а затем потоковая обработка.
Это были микропакетная обработка, а затем потоковая обработка.
Как работает микропакетная обработка?
Микропакетная обработка ускорила цикл, поэтому данные можно было загружать гораздо чаще, иногда с шагом в несколько секунд. Технологии микропакетной загрузки включают Fluentd, Logstash и Apache Spark Streaming.
Микропакетная обработка очень похожа на традиционную пакетную обработку, поскольку данные обычно обрабатываются как группа. Основное отличие состоит в том, что партии меньше и обрабатываются чаще.Микропакет может обрабатывать данные с определенной частотой — например, вы можете загружать все новые данные каждые две минуты (или две секунды, в зависимости от доступной вычислительной мощности). Или микропакет может обрабатывать данные на основе какого-либо флага события или триггера (например, данные больше 2 мегабайт или содержат более дюжины фрагментов данных).
Хотя это не настоящая обработка в реальном времени, микропакетная обработка изначально была достаточной для поддержки некоторых сценариев использования «в реальном времени», в которых данные не обязательно должны быть актуальными. Например, у вас могут быть корпоративные информационные панели, которые обновляются каждые 15 минут или ежечасно. Или вы можете собирать журналы сервера через небольшие регулярные промежутки времени для ведения исторической записи, а не для реальных случаев использования в реальном времени, таких как обнаружение вторжений.
Например, у вас могут быть корпоративные информационные панели, которые обновляются каждые 15 минут или ежечасно. Или вы можете собирать журналы сервера через небольшие регулярные промежутки времени для ведения исторической записи, а не для реальных случаев использования в реальном времени, таких как обнаружение вторжений.
Сравнение микропакетной обработки и потоковой обработки
Мир ускорился, и есть много вариантов использования, для которых микропакетная обработка просто недостаточно быстра. В настоящее время организации обычно используют микропакетную обработку в своих приложениях, только если они приняли архитектурные решения, препятствующие потоковой обработке.Например, магазин Apache Spark может использовать Spark Streaming, который, несмотря на свое название и использование вычислительных ресурсов в памяти, на самом деле является расширением для микропакетной обработки Spark API.
Сейчас технологии потоковой обработки становятся все популярнее в современных приложениях. Поскольку за последнее десятилетие объем данных увеличивался, предприятия обратились к обработке в реальном времени, чтобы реагировать на данные ближе к тому времени, когда они создаются, для решения различных сценариев использования и приложений.В некоторых случаях микропакетная обработка выполнялась «достаточно в реальном времени», но все чаще организации признают, что потоковая обработка с использованием технологии в памяти — в облаке или локально — является идеальным решением.
Поскольку за последнее десятилетие объем данных увеличивался, предприятия обратились к обработке в реальном времени, чтобы реагировать на данные ближе к тому времени, когда они создаются, для решения различных сценариев использования и приложений.В некоторых случаях микропакетная обработка выполнялась «достаточно в реальном времени», но все чаще организации признают, что потоковая обработка с использованием технологии в памяти — в облаке или локально — является идеальным решением.
Потоковая обработка позволяет приложениям реагировать на новые события данных в момент их создания. Вместо того, чтобы группировать данные и собирать их через некоторый заранее определенный интервал, системы потоковой обработки собирают и обрабатывают данные немедленно по мере их создания.
Примеры использования потоковой обработки
В то время как самые агрессивные разработчики измеряют производительность технологий микропакетной обработки в миллисекундах — например, рекомендуемый нижний предел пакетных интервалов Spark Streaming составляет 50 миллисекунд из-за связанных накладных расходов — разработчики измеряют производительность потоковой обработки за один раз.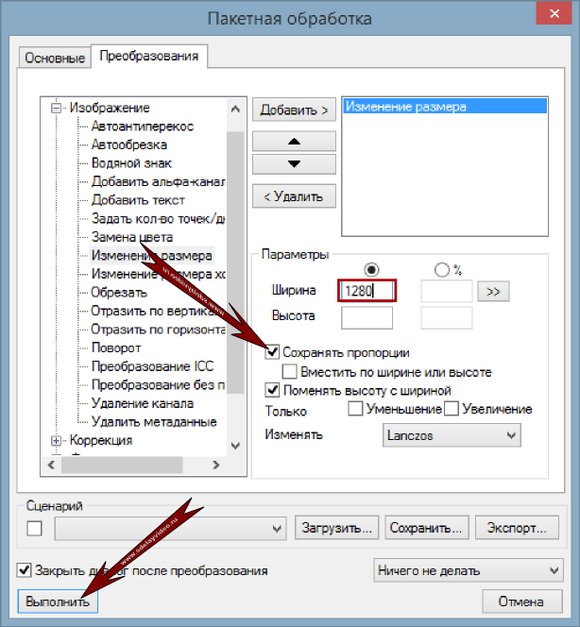 цифра миллисекунды. Например, в этом сообщении блога о потоковой технологии для розничных банков автор объясняет, как крупный процессор кредитных карт выполняет основной рабочий процесс сбора и обработки данных для обнаружения мошенничества за 7 миллисекунд.
цифра миллисекунды. Например, в этом сообщении блога о потоковой технологии для розничных банков автор объясняет, как крупный процессор кредитных карт выполняет основной рабочий процесс сбора и обработки данных для обнаружения мошенничества за 7 миллисекунд.
Приложения, которые включают потоковую обработку, могут реагировать на новые данные немедленно по мере их создания, а не после того, как данные пересекают предварительно определенный порог. Это критически важная возможность для таких случаев использования, как обработка платежей, обнаружение мошенничества, обнаружение аномалий IoT, безопасность, оповещение, маркетинг в реальном времени и рекомендации. Если ваш вариант использования либо включает данные, которые являются наиболее ценными на момент их создания, либо требует ответа (т. Е. Сбора и обработки данных) во время генерации данных, потоковая обработка подходит именно вам.
Учитывайте, когда вы проводите кредитной картой в кассу в местном продуктовом магазине.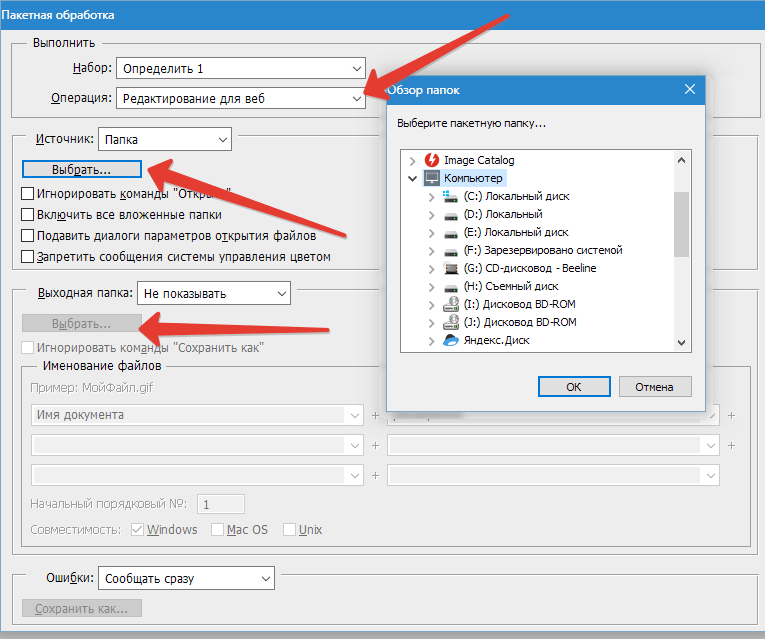 Вы ожидаете или, по крайней мере, надеетесь, что система обработки платежей немедленно подтвердит, что вы не заявили о своей кредитной карте об утере или краже, и транзакция будет авторизована, с учетом того, что в большинстве случаев данные передаются по сети и обратно. Это требует потоковой обработки. Теперь представьте, что вы последний покупатель в магазине и проводите пальцем по карте, но платежная система построена на системе микропакетной обработки с пакетами, установленными для обработки при появлении 10 новых транзакций.Вы будете ждать дольше, чем необходимо.
Вы ожидаете или, по крайней мере, надеетесь, что система обработки платежей немедленно подтвердит, что вы не заявили о своей кредитной карте об утере или краже, и транзакция будет авторизована, с учетом того, что в большинстве случаев данные передаются по сети и обратно. Это требует потоковой обработки. Теперь представьте, что вы последний покупатель в магазине и проводите пальцем по карте, но платежная система построена на системе микропакетной обработки с пакетами, установленными для обработки при появлении 10 новых транзакций.Вы будете ждать дольше, чем необходимо.
Технологии потоковой обработки, такие как Hazelcast Jet с Hazelcast IMDG (и в качестве управляемого сервиса, как Hazelcast Cloud), позволяют собирать, обрабатывать и анализировать данные в реальном времени в масштабе по мере их создания.
Связанные темы
Обработка потоков
Обработка потоков в реальном времени
Обработка потока событий
Направленный ациклический граф (DAG)
Дополнительная литература
Роль потоковых технологий в розничном банковском деле
Пакетная обработка с помощью SOA — Dovel Technologies
Пакетная обработка с SOA
Хотя обычно их считают артефактом устаревших вычислений, пакетные процессы остаются жизненно важными для сегодняшних предприятий, работающих в режиме реального времени. За системами реального времени, которые обеспечивают работу предприятия в реальном времени, таких как выполнение заказов клиентов, управление счетами, планирование и оптимизация цепочки поставок или системы финансовой торговли, стоят регулярно обновляемые бизнес-системы вспомогательного офиса. Сегодня пакетные процессы остаются важными по одной ключевой причине: просто неэффективно повторно создавать полный прогноз или бизнес-план каждый раз, когда бизнес обрабатывает отдельное событие, такое как входящий заказ клиента. Предприятиям реального времени действительно требуются системы, которые могут поддерживать динамические процессы; однако лучше всего зарезервировать эту емкость для аспектов данных или процессов на наиболее изменчивых высокоскоростных рынках.
Тем не менее, хотя потребность в пакетных процессах не изменилась, характер пакетной обработки сегодня определенно изменился. Например, в то время как запланированные пакетные процессы остаются актуальными для связанных со временем процессов, таких как отчетность на конец периода, предприятиям в реальном времени может потребоваться большая гибкость для адаптации к временным или постоянным колебаниям рынка или к запланированным или незапланированным изменениям в базовой ИТ-инфраструктуре. Компании сталкиваются с новыми требованиями к соблюдению все более строгих нормативных требований.Это может диктовать необходимость в управляемых политиками рабочих процессах с возможностью динамического запуска пакетных процессов при возникновении определенных сценариев. Например, нарушение закона Сарбейнса-Оксли может вызвать откат и новый раунд обновления основных финансовых систем, выходящий за рамки обычного графика.
Компании сталкиваются с новыми требованиями к соблюдению все более строгих нормативных требований.Это может диктовать необходимость в управляемых политиками рабочих процессах с возможностью динамического запуска пакетных процессов при возникновении определенных сценариев. Например, нарушение закона Сарбейнса-Оксли может вызвать откат и новый раунд обновления основных финансовых систем, выходящий за рамки обычного графика.
Сервисно-ориентированная архитектура (SOA) предоставляет предприятиям возможность предоставлять информацию и процессы как автономные сервисы, которые могут обмениваться данными и взаимодействовать друг с другом стандартным, слабосвязанным образом.Хотя обычно складывается впечатление, что службы предоставляют доступ к бизнес-процессам, процессам обработки данных или функциональности приложений, они также хорошо подходят для раскрытия самих процессов, которые управляют пакетными рабочими нагрузками. SOA позволяет бизнесу создавать гибкие композиции сервисов, которые реализуют бизнес-процессы или ИТ-процессы в слабосвязанной манере, что имеет важные последствия для предоставления ИТ-услуг и пакетных процессов, являющихся его частью.
Развитие пакетной обработки
За прошедшие годы пакетная технология превратилась из автоматизации на основе сценариев в правила или автоматизацию рабочих нагрузок на основе политик.ИТ-специалисты давно стремились автоматизировать выполнение пакетных заданий, первоначально с помощью инструментов, которые автоматически объединяли их в расписание. По мере того как окна пакетной обработки сокращались, ИТ-организации внедряли технологии управления заданиями, позволяющие им оптимизировать использование ограниченных ресурсов в более короткие сроки. Автоматизация рабочих нагрузок — это кульминация инноваций в автоматизации заданий, позволяющая адаптировать ее к потребностям предприятия реального времени с помощью настраиваемых рабочих процессов на основе политик. По сравнению с традиционными методами автоматизации заданий настраиваемые рабочие процессы гораздо более гибкие и удобные в обслуживании.
Однако цель изменилась. Вместо оптимизации временных окон или потребления ресурсов в центре обработки данных, сегодня миссия пакетной обработки расширила поддержку бизнеса. На предприятии в реальном времени современные пакетные операции трансформируются из статического, часто автономного процесса в динамический компонент приложения или составного бизнес-процесса. Цели могут включать в себя ускорение реагирования, повышение корпоративной прозрачности и предоставление ИТ-отделам возможности принять более бизнес-ориентированный и ориентированный на соблюдение подход подход к управлению собственными операциями.
Ключ к достижению этих целей — последовательность и гибкость. При использовании традиционных, жестко запрограммированных или ручных подходов обеспечение единообразия пакетных процессов часто оказывалось неудачным решением. Пакетная обработка и ее преемница автоматизация рабочих нагрузок развивались со временем, с последними инновациями, добавляющими рабочие процессы на основе политик или правил, которые превращают пакетные задания в повторяемые рабочие процессы.
В конечном итоге SOA обеспечивает архитектурную основу, которая воплощает это видение в жизнь: вызывая пакетные процессы как услугу, они становятся неотъемлемыми компонентами составляемых бизнес-процессов, которые обеспечивают работу предприятия в реальном времени. Например, посредством включения услуг автоматизация рабочих нагрузок может стать расширением приложений, начиная от управления цепочкой поставок и заканчивая службой ИТ-поддержки. Давняя пасынок работы центра обработки данных, автоматизация рабочих нагрузок превращается в первоклассного гражданина предприятия реального времени.
Например, посредством включения услуг автоматизация рабочих нагрузок может стать расширением приложений, начиная от управления цепочкой поставок и заканчивая службой ИТ-поддержки. Давняя пасынок работы центра обработки данных, автоматизация рабочих нагрузок превращается в первоклассного гражданина предприятия реального времени.
Внедрение автоматизации рабочих нагрузок как услуги может также способствовать культурным изменениям, которые объединяют ИТ-операции, разработку программного обеспечения и бизнес. Как правило, пакетные задания либо планируются, либо «перебрасываются через стену» от бизнеса к операциям.Когда пакетные рабочие нагрузки или рабочие процессы, представленные как службы, становятся расширениями приложения, разработчики, которые проектируют или настраивают приложение, теперь могут учитывать спрос на ИТ-инфраструктуру, указав логику или правила, по которым корпоративные системы могут запрашивать пакетные службы. Автоматизация рабочих нагрузок является ключом к тому, чтобы сделать пакетное окно первоклассным гражданином предприятия реального времени, что требует расширения роли автоматизации рабочих процессов с ИТ до инструмента, управляемого бизнесом.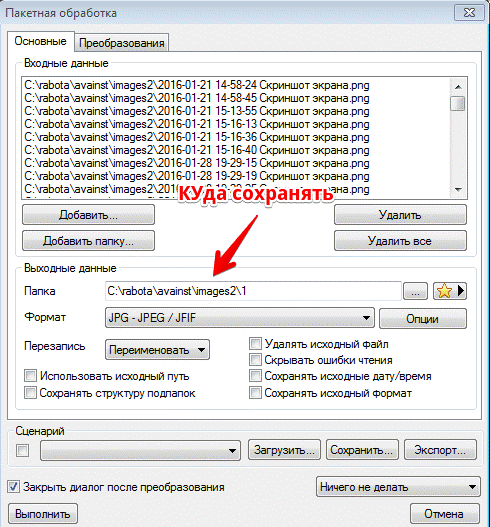
Следовательно, меняется и цель автоматизации рабочих нагрузок.Вместо того, чтобы оптимизировать ИТ-службы собственных рабочих процессов обновления центра обработки данных, теперь на месте водителя находятся приложения или бизнес-процессы, запускающие рабочие нагрузки при возникновении определенных бизнес-событий или сценариев. Для этого требуется механизм рабочих процессов, ориентированный на бизнес-процессы, для автоматизации заданий и механизм бизнес-правил для обеспечения управления рабочим процессом на основе политик. В рабочем процессе, управляемом бизнесом, запросы от приложений, хранимых процедур базы данных или бизнес-процессов запускают рабочие нагрузки (которые могут состоять из одного или нескольких пакетных заданий) в результате явных бизнес-правил или политик.
Например, когда происходит заказ для определенного артикула продукта, для автоматического запуска новых рабочих нагрузок могут использоваться следующие правила:
- Если поступает несколько неожиданных заказов, измените графики отгрузки, но не меняйте планы цепочки поставок.
- В случае непредвиденного прогона продукта создайте новый прогноз спроса.
- Если прогон вызывает фактическую или потенциальную нехватку продукта, повторно создайте планы запасов, закупок, распределения и спроса.
В этих сценариях рабочие нагрузки больше не сосредоточены исключительно на оптимизации обновлений баз данных в центре обработки данных. Вместо этого они стали неотъемлемыми компонентами бизнес-процессов цепочки поставок, ориентированных на спрос. Пакетные процессы будут представлены как Сервисы, к которым вы, возможно, захотите получить доступ в реальном времени. Идея пакета состоит в том, что процесс предопределен (так что пакет не является гибким процессом), но он будет отображаться как служба, которая может быть использована в гибком процессе. В традиционных рабочих нагрузках пакет может быть запланирован как часть повседневной деятельности, но пакет, ориентированный на службы, может выполняться по запросу.С точки зрения сервис-ориентированности, контракт и политика сервиса должны указывать, сколько раз пакет может быть выполнен за один день, сколько времени требуется для работы пакета, а также любые другие зависимости службы или данных.
Вклад SOA в автоматизацию рабочих нагрузок
SOA — это представление информации и процессов как автономных сервисов, которые могут обмениваться данными и взаимодействовать друг с другом стандартным, слабосвязанным образом, что позволяет бизнесу создавать гибкие композиции сервисов, реализующих деловые процессы.В конечном итоге SOA позволяет ИТ-специалистам более эффективно согласовываться с бизнесом, поскольку меняет способ предоставления ИТ-решений решений. Автономный характер Сервисов и стандартные возможности подключения позволяют ИТ-специалистам быстро составлять решения за счет повторного использования существующих Сервисов, что приводит к более быстрой окупаемости по сравнению с традиционными способами разработки, модификации и интеграции обычных монолитных программных приложений.
Хотя SOA обычно ассоциируется с функциональностью, предоставляемой программными приложениями и / или составными бизнес-процессами, она также может предоставлять процессы ИТ-инфраструктуры, такие как автоматизация рабочих нагрузок, в качестве услуг. При использовании SOA бизнес-события запускают определенные типы заданий. По сути, работа становится частью составного сервис-ориентированного бизнес-приложения. Инфраструктура SOA в сочетании со стандартами, используемыми при реализации SOA, способствует действительно слабой связи, при которой бизнес-логика, бизнес, правила и спецификации заданий могут изменяться, не влияя на другие компоненты. Например, система автоматизации рабочих нагрузок может вызвать службу пакетного обновления в результате запуска системой Business Intelligence запланированной операции извлечения-преобразования-загрузки (ETL) в хранилище данных.Если пользователь изменяет саму свою ETL-систему или некоторые процедуры преобразования, это изменение сохраняется внутри службы ETL и не должно влиять на службу рабочей нагрузки.
При использовании SOA бизнес-события запускают определенные типы заданий. По сути, работа становится частью составного сервис-ориентированного бизнес-приложения. Инфраструктура SOA в сочетании со стандартами, используемыми при реализации SOA, способствует действительно слабой связи, при которой бизнес-логика, бизнес, правила и спецификации заданий могут изменяться, не влияя на другие компоненты. Например, система автоматизации рабочих нагрузок может вызвать службу пакетного обновления в результате запуска системой Business Intelligence запланированной операции извлечения-преобразования-загрузки (ETL) в хранилище данных.Если пользователь изменяет саму свою ETL-систему или некоторые процедуры преобразования, это изменение сохраняется внутри службы ETL и не должно влиять на службу рабочей нагрузки.
The ZapThink Take
В разгар пузыря доткомов считалось, что Интернет должен изменить все в бизнесе. Хотя Интернет помог предприятиям наладить новые связи как с деловыми партнерами, так и с клиентами, он не изменил основ ведения бизнеса или управления ИТ-системами. Аналогичным образом, сегодняшнее развитие предприятий реального времени не устранило необходимость в эффективной пакетной обработке. Используя сервисно-ориентированную архитектуру (SOA), предприятия могут развивать пакетные рабочие нагрузки от автономных операций центра обработки данных до компонентов, которые являются неотъемлемой частью составных сервис-ориентированных бизнес-приложений. Там, где автоматизация рабочих нагрузок и пакетная обработка когда-то были непонятными задачами, низведенными глубоко в организации, они стали критически важными услугами, предоставляемыми как часть архитектуры предприятия.
Аналогичным образом, сегодняшнее развитие предприятий реального времени не устранило необходимость в эффективной пакетной обработке. Используя сервисно-ориентированную архитектуру (SOA), предприятия могут развивать пакетные рабочие нагрузки от автономных операций центра обработки данных до компонентов, которые являются неотъемлемой частью составных сервис-ориентированных бизнес-приложений. Там, где автоматизация рабочих нагрузок и пакетная обработка когда-то были непонятными задачами, низведенными глубоко в организации, они стали критически важными услугами, предоставляемыми как часть архитектуры предприятия.
Загрузить полную пакетную обработку с отчетом SOA здесь
Сборочная линияи периодический процесс | Small Business
Автор Chron Contributor Обновлено 23 июля 2020 г.
Пакетная обработка или серийное производство — это уменьшенная версия конвейерного производства. Продукция производится группами, а не непрерывными потоками, как на сборочных линиях. Однако серийное производство также создает задержки, потому что компании должны останавливать производственные линии между партиями.Эти задержки могут быть проблематичными, если мешают своевременной доставке продуктов покупателям. Примените эти преимущества и недостатки серийного производства по сравнению с непрерывным производством в своем собственном бизнесе, чтобы определить, что лучше всего подходит для ваших обстоятельств.
Однако серийное производство также создает задержки, потому что компании должны останавливать производственные линии между партиями.Эти задержки могут быть проблематичными, если мешают своевременной доставке продуктов покупателям. Примените эти преимущества и недостатки серийного производства по сравнению с непрерывным производством в своем собственном бизнесе, чтобы определить, что лучше всего подходит для ваших обстоятельств.
Сборочная линия: Плюсы
Сборочная линия, или производственная линия, позволяет производителям быстро и эффективно производить большое количество изделий. По данным Университета Уилламетт, каждый рабочий или машина выполняет определенную задачу по созданию части продукта по мере его продвижения по производственной линии, пока элемент не будет готов.Сборочное производство часто работает в пользу экономии на масштабе, что означает снижение средней стоимости производства продукта за счет увеличения его производства. Например, производители могут получать скидки на материалы, необходимые для изготовления продукта, когда они покупают эти материалы в больших количествах для больших производственных партий.
Сборочная линия: Cons
Контролировать отходы и финансовые потери при производстве сборочной линии может быть сложно. Большие производственные линии часто включают в себя дорогие сборочные машины, которые производители могут использовать только с высокой производительностью.Однако крупный производственный цикл увеличивает вероятность производственных ошибок, из-за которых получается дефектная продукция, которую производитель не может продать. Большой объем производства также может привести к тому, что производители застрянут с большим количеством товаров, которые нельзя продать из-за падения потребительского спроса.
Пакетный процесс: плюсы
Пакетная обработка в производстве может быть полезна для малых предприятий, у которых нет достаточного капитала для запуска непрерывных производственных линий, согласно Lumen Learning. Это также помогает компаниям избежать большого количества отходов.В качестве примера серийного производства владелец пекарни может принять заказ на 3000 тортов и изготовить их отдельными партиями по 1000 штук каждая. Владелец не потеряет все торты, если одна партия испортится из-за производственных проблем.
Владелец не потеряет все торты, если одна партия испортится из-за производственных проблем.
Серийное производство также полезно для сезонных товаров, поскольку производство может начинаться и останавливаться в соответствии с сезонными производственными потребностями. Иногда розничные торговцы соглашаются хранить в своих магазинах новые товары, которые в конечном итоге не продаются хорошо, поэтому они отменяют будущие заказы. В таких случаях пакетная обработка не позволяет производителям вкладывать большие средства в новые продукты, которые могут не продаваться.
Пакетный процесс: против
Производство продуктов партиями неэффективно из-за времени простоя, связанного с процессом. Производители обычно должны останавливать машины и перенастраивать их для каждой новой партии, которую они производят. Они также должны пройти повторные испытания станков, чтобы убедиться, что их производительность соответствует целевому показателю для производимой продукции.